ソフトウェア高速化の鍵は「並列化」:いま注目される並列化技術を知る
従来は高級サーバーでしか採用されていなかったマルチCPU/マルチコアが、一般的なPCにも普及しつつある。このようなマルチCPU/マルチコア環境において、高速に動作するアプリケーションを開発するために注目されているのが「並列化」技術である。本記事では、この並列計算の基本的な考え方やそのメリット、利用できるライブラリなどについて紹介する。
ソフトウェアをより高速に動作せたい、というのはすべてのソフトウェア開発者にとって共通の悩みだろう。ユーザーにとって、高速なソフトウェアは作業効率が向上するだけでなくコスト削減にもつながる。そして、ソフトウェアを高速に動作させるための技術として現在注目を浴びているのが「並列化」である。
並列処理という概念自体は、さほど新しいものではない。スーパーコンピュータを用いたHPC(High-Performance Computing)の分野では、従来から高速化のために並列処理が利用されていた。スーパーコンピュータは並列処理を高速に実行する仕組みを備えており、これを利用することで大幅な高速化が期待できたからだ。
では、なぜ今になって並列化が注目されているのだろうか。その要因としてはCPUの処理能力向上ペースの鈍化と、それを補うためのマルチコア化が挙げられる。
CPUの動作クロックは1990年代後半から2000年代中頃にかけて急速に向上した。しかし、CPUの動作クロックが向上するほど消費電力や発熱量は多くなる傾向にあり、現在ではこれらが無視できない問題となっている。そこで現在CPUメーカー各社が行っているのが、コア数を増やすことによりCPUのパフォーマンスを高める試みである。
マルチコアCPUでは並列化が有用に
かつてはマルチCPU/マルチコアCPUというと、ハイエンドPCやサーバーにしか搭載されないものであったが、現在ではインテルのメインストリーム向けCPUであるCore 2シリーズだけでなく、エントリ向けのCeleronまでもがデュアルコア化されている。さらにハイエンドクラスのPCはクアッドコアCPUを搭載するようになり、現在インテルのデスクトップ向け最上位CPUである「Core i7」シリーズでは、1CPUで4コア+Hyper-Threadingによる8スレッド同時実行が可能となっている。
IDCの調査によると、デスクトップPC/モバイルPC/PCサーバーの全分野において、2008年の時点でマルチコアCPUのシェアは80%以上とのことである。さらにそのシェアは2010年には100%になると予測されているそうだ(図1)。
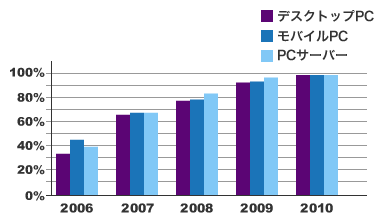
複数の処理が並列して動作するマルチタスクOS環境では、CPUのマルチコア化によるパフォーマンス向上の恩恵を受けやすい。また並列化されたプログラムであれば、複数のCPUを効率的に利用することで処理速度の向上が期待できる。
これから90年代~2000年代初頭のように、CPUの処理能力が急激に上昇するということは考えにくい。一方でデュアルコア/クアッドコアといったマルチコアCPUの普及はますます進むと予想されている。つまり、これからCPUの能力を最大限に引き出そうとすると、並列処理は避けて通れない技術になっているのである。
並列処理プログラミングをサポートする環境が整いつつある
とはいっても、並列処理にもデメリットはある。まず大きな問題は、実装やデバッグが面倒という点であろう。プログラムを並列化するには後述するように複数のスレッドやプロセスを利用するのだが、複数のスレッドやプロセスが正しく協調して動作するよう、スレッド/プロセス間で同期や通信を行わせる必要がある。また、既存のアルゴリズムの多くは並列化が考慮されていないため、アルゴリズム自体を並列化に適したものに改良する必要があることが多い。
さらに、並列化することで逆に処理が遅くなる可能性もある。一般的には実行したい処理のすべてが並列化できるわけではなく、また、並列化にはオーバーヘッドも生じるからだ。
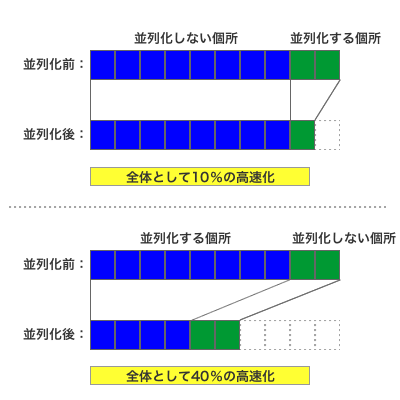
これについては「アムダールの法則」が有名である。たとえば、プログラムの中で実行時間のうち5分の1の時間を占めている処理を並列化できたとしよう。この場合、並列化によってその処理が2倍の速度で実行できたとしても、全体としては処理時間は10%しか短縮できない。一方、実行時間の5分の4を占める処理を2倍の速度で実行できるようになれば、処理時間は40%も短縮できる。
ここでは並列化のオーバーヘッドを考慮していないが、もし並列化を行うことで10%余計な時間が必要になったとすると、前者は並列化を行ったとしても最終的な処理時間は変わらない。つまり、並列化を行う際には時間のかかっている処理を適切に並列化できるよう、十分な分析が必要なのである。
このような背景から、並列処理の実装やデバッグをできるだけ簡略化できるよう、並列処理を簡単に記述できる言語規格や開発環境、開発ツールなどが近年登場してきている。並列化をサポートする言語規格としては、C/C++やFortranで利用できる「OpenMP」がその代表だ。また、自動並列化などの機能を搭載したコンパイラやデバッグツール、パフォーマンス測定ツールなどからなる開発スイート「インテル Parallel Studio」といった製品もリリースされている。
それ以外にも、「Erlang」など並列化をサポートしたプログラミング言語が最近注目を浴びているほか、マイクロソフトがC#と連携して利用できる並列プログラミング言語「Axum」を公開するなど、並列プログラミングを行う環境は徐々に整備されつつある。
コラム 並列化と問題の分割
プログラムを並列化する際には、実行する処理をどのように複数のスレッド/プロセスに割り当てるか、というのが問題になる。これを、「問題の分割」と呼ぶ。
問題の分割方法としては、大きく分けて2通りがある。1つは、同一の処理を複数のスレッド/プロセスに割り当てる、というもので、もう1つは異なる処理を複数のスレッド/プロセスに割り当てる、というものだ。
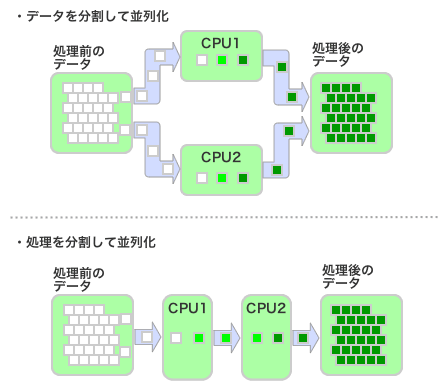
前者は処理したいデータを簡単に分割できる場合に有効である。また、後者はいわゆる「パイプライン処理」的な処理に適したもので、処理を複数の段階(パイプライン)に分け、それぞれのパイプラインを並列に動かすものである。こちらは、連続的にデータを処理する場合などに適している。
たとえば画像処理などでは前者の処理が使われることが多く、また動画ファイルのエンコード/デコード処理などでは後者が利用される例が多い。
並列処理の実装方法
以上で述べてきたとおり、現在では並列処理がトレンドになりつつあり、プログラムを並列化する手法についても簡単な物から複雑なものまで様々なものが登場している。以下では、現在利用できる並列化の方法について紹介しておこう。
プロセス/スレッドを利用した実装並列処理の実装としてもっともプリミティブなものが、プロセス/スレッドを利用した実装である。これは、並列化したい処理を異なるプロセス/スレッドとして動作させる、というものだ。たとえばWindows環境では_beginthread()関数や_beginthreadex()関数、CreateThread()関数などを利用することで、特定の関数を別スレッドで実行できる。また、UNIX環境では主にサーバーアプリケーションなどにおいて、fork()関数を用いてプロセスを生成して処理を行わせる例が多いほか、POSIXスレッド(pthreads)という関数群を利用してマルチスレッド処理を行わせることができる(表1)。
| OS環境 | プロセス/スレッド | 利用できる関数 | |
|---|---|---|---|
| Windows | スレッド生成 | Cランタイムライブラリ | _beginthread()、_beginthreadex()、 |
| Windows API | CreateThread() | ||
| MFC | CWinThreadクラス、AfxBeginThread() | ||
| プロセス生成 | CreateProcess() | ||
| UNIX/Linux | スレッド生成(POSIXスレッド) | pthread_create() | |
| プロセス生成 | fork() | ||
プロセス/スレッドを利用すると柔軟に処理を実装できる半面、共有データの管理やプロセス/スレッドごとの同期についても自前で実装する必要があるため、工数が増えるのが問題である。
現代のマルチタスクOSはプロセス/スレッド同士が安全に情報をやりとりできる仕組みを備えているものの、このような処理は一般的に時間的コストが高く、また設計を間違えるとデッドロックなども発生する可能性がある。特に並列化されたプログラムはデバッグが難しく、「特定の状況でのみ問題が発生する」といったいやらしいトラブルが発生しやすい。
| プロセスとスレッドの違い |
|---|
|
プロセスおよびスレッドは、どちらもCPUが処理を行う単位であるが、プロセスは個別にメモリ空間を持つのに対し、同じプロセスから作られたスレッドはメモリ空間を共有するというのが異なる点である。 そのため、複数のプロセスを使って並列処理を行う場合、プロセス同士が通信を行い、共有するデータをやりとりする仕組みが必要となる。いっぽう複数のスレッドを使った並列処理の場合は、同一のメモリ空間をそれぞれのスレッドが使用するため、同じ変数を共有して利用でき、スレッド同士の通信が最小限で済むというメリットがある。また、プロセスの生成は一般に重い処理であることが多く、並列化によるオーバーヘッドが大きくなる傾向がある。そのため、一般的なアプリケーションで並列処理を行う場合はスレッドを利用する場合が多い。 |
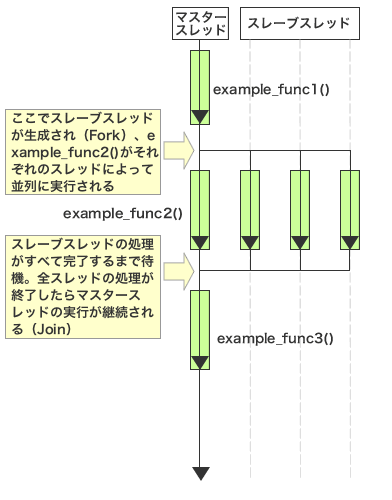
スレッド/プロセスを明示的に利用して並列処理を実装する場合、並列して処理させたい個所を関数として実装する必要がある。しかし、一般のプログラムにおいては、並列化したい個所というのは特定のループやブロックのみである場合が多い。OpenMPは、プログラムのソースコード中に特定のプラグマを挿入することで並列化すべき個所を指定し、コンパイラに並列化を行わせるものである。
たとえば次の例は、OpenMPを使用してforループを並列化する例である。
example_func1();
#pragma omp parallel for
for(i = 0; i < 100; i++ ) {
example_func2(i); /* 並列実行する処理 */
}
example_func3();
「#pragma omp parallel for」プラグマは、このプラグマに続くforループを並列化するようコンパイラに指示するものだ。このように記述されたプログラムは、以下の図4のように関数example_func2()のみが並列実行され、それ以外の処理についてはシングルスレッドで実行される。
前述のとおり、スレッド/プロセスを利用する並列化は実装が複雑になりやすく、いっぽうでOpenMPは手軽に利用できるものの、プラグマを利用するため可読性や柔軟性に欠け、またC++では利用しにくいという問題があった。インテルが開発し、現在はオープンソースライセンス(GPL)で公開されているThreading Building Blocks(TBB)は、WindowsやLinux、Mac OS XやFreeBSDといったUNIX系OSで利用できるC++向けの並列プログラミングライブラリで、OpenMPよりも柔軟ながら、スレッド/プロセスを利用するよりは容易に並列プログラムを作成できるのが特徴である。
次の例は、TBBを用いてforループを並列化させるサンプルコードである。
/* 処理をクラスとして作成 */
class ExampleObj
{
void operator() (const blocked_range<int>& range) const
{
for(int i = range.begin(); i != range.end(); i++)
example_func2(i); /* 並列実行する処理 */
}
};
:
:
/* 処理を呼び出す部分 */
/* gsizeには分割粒度を指定 */
int gsize = 10;
ExampleObj obj;
parallel_for( blocked_range<int>(0, 100, gsize), obj);
そのほかTBBには、データを格納するためのスレッドセーフなコンテナやmutexなどの同期機構なども用意されている。
「コードを書かない」並列プログラミング
スレッド/プロセスを活用したり、OpenMPやTBBを利用する以外にも、特別なコードを書かずに並列化を実装する手段がある。あらかじめアルゴリズムが並列化されて実装されているライブラリを利用したり、自動並列化機能を備えたコンパイラを利用する、というものだ。
並列化済みライブラリの利用たとえばインテルの「Math Kernel Library(MKL)」や「Integrated Performance Primitives(IPP)」といったライブラリは、内部処理があらかじめ並列化されているため、これらのライブラリを利用するだけで特に意識することなしに処理の並列化が行える。MKLは数学・科学計算で多用される浮動小数点演算や行列処理、IPPでは動画/音声コーデックや暗号化といった処理が用意されており、これらの分野のアプリケーションを作成するなら検討したいライブラリである。ただし、これらのライブラリでカバーされていない分野では利用できないのが欠点ではある。
コンパイラによる自動並列化の利用「インテル コンパイラー」や「インテル Parallel Composer」といったコンパイラ製品には、ソースコード中のループの個所などを自動的に並列化する「自動並列化」機能が用意されている。自動並列化の使用の有無や、並列化を行うスレッショルドなどをコンパイルオプションで指定するだけで利用でき手軽ではあるものの、単純なループしか並列化できず、またプログラムによってはあまり高速化が期待できない点には注意が必要である。
パフォーマンス向上に活用したい並列プログラミング
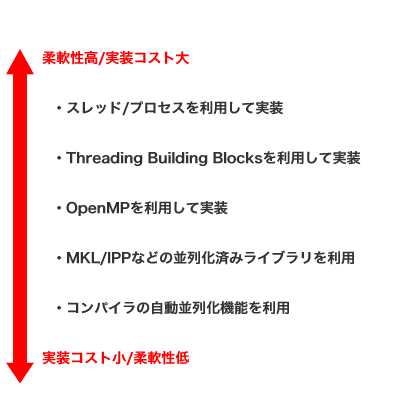
このように、C/C++で利用できる並列化技術にはさまざまなものがある。スレッド/プロセスを利用した並列化は複雑だが処理を柔軟に記述することが可能だ。いっぽうOpenMPは手軽ではあるものの、若干融通が利かない部分もある。並列化を行う際は、必要とする状況に応じて、適切な実装・実現方法を選択するようにしたい(図5)。
並列処理はまだ一般には歴史が浅いため、「難解」「バグを産みやすい」「設計が難しい」といった、ネガティブな印象を持つ人も多いだろう。しかし、ライブラリやデバッガといった周辺ツールの充実により、以前よりも利用しやすくなっているといえる。CPU単体のパフォーマンス向上が鈍化しつつあり、将来的にマルチコアCPUの普及が予想されている現在では、負荷の高い処理を高速に実行するためには並列化の導入が不可欠ともいえるだろう。