サンプルコードで知るParallel Studioの並列化機能
「インテル Parallel Studio」はマルチスレッドやOpenMPなどを使用した、並列処理を行うプログラムの開発を支援するツールである。本記事では、Parallel Studioに含まれる並列化機能や強力な最適化機能、並列化関連ライブラリ、デバッガ、プロファイラといった機能や、使い方の例などを紹介していく。
Parallel Studioは、「インテル Parallel Composer」(以下、Parallel Composer)および「インテル Parallel Inspector」(以下、Parallel Inspector)、「インテル Parallel Amplifier」(以下、Parallel Amplifier)という3つのコンポーネントと、今後追加が予定されている「インテル Parallel Advisor」から構成されている開発ツールだ。詳細については別記事で詳しく解説を行っているが、プログラムの並列化を行うために有用な並列化機能や強力な最適化機能、並列化関連ライブラリ、デバッガ、プロファイラといった機能が含まれている。これらがどのようなものなのか、またどのようなことができるのか、興味を持っているユーザーも多いだろう。そこで本記事では、Parallel Studioに付属するサンプルコードを例に、Parallel Studioの機能を使ってプログラムを並列化するステップを順に追って紹介していこう。
なお、Parallel StudioはVisual Studioのプラグインとしてインストールされるが、コンパイラやリンカなどはコマンドラインからも利用できる。これら実行ファイルやドキュメントなどは、デフォルトではProgram Filesフォルダ以下の「Intel\Parallel Studio」ディレクトリ以下にインストールされる。ディレクトリ構成は下記の表1のとおりだ。それぞれのディレクトリ以下のbin\以下に実行ファイルおよび関連DLLが、lib\以下にライブラリが、include\以下にヘッダファイル等が含まれるほか、各種ドキュメントやサンプルなども用意されている。
| ディレクトリ | 含まれる内容 |
|---|---|
| Amplifier | Parallel Amplifierのプラグインおよび関連ライブラリ |
| Composer | Parallel Composerのプラグインおよび関連ライブラリ |
| Inspector | Parallel Inspectorのプラグインおよび関連ライブラリ |
| Samples | サンプルコード |
Parallel StudioはVisual StudioのIDEに統合されるため、Visual Studioを利用して開発しているソフトウェアであれば、非常に簡単に利用できる。以下ではParallel Studioに付属しているサンプル「NQueens」で、Parallel Studioの利用例を紹介しよう。
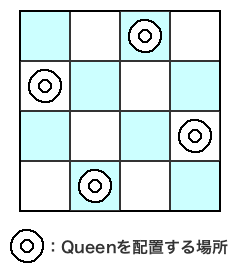
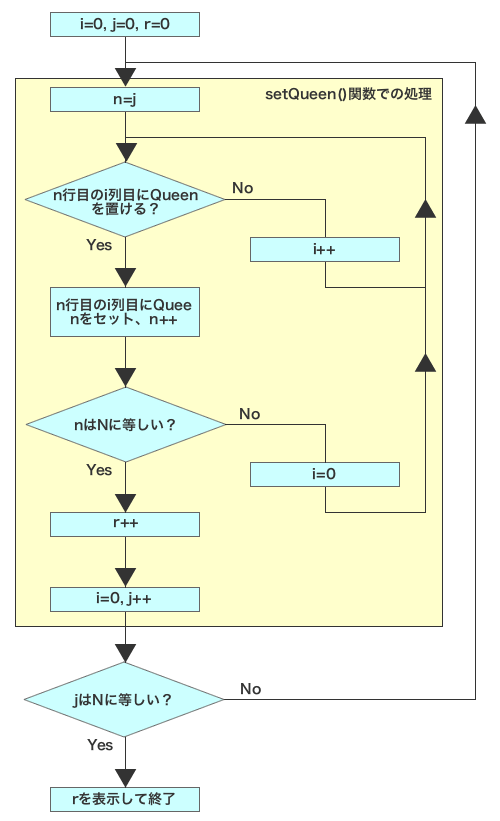
NQueensは、ボードゲームのチェスをベースにした問題であり、N×Nサイズのチェス盤上に、お互いに駒を取られないような位置にN個のクイーンを配置するパターンが何通りあるかを求めるものである(図1)。サンプルコード(nq_serial.cpp)では、図2のようなアルゴリズムで解法を求めており、引数に盤面のサイズおよび配置するクイーンの数を指定する数値Nを与えてプログラムを実行すると、配置パターン数が計算される。
なお、Parallel Studioの評価版はエクセルソフトのWebサイトからダウンロードできる。今回使用しているサンプルも付属しているので、興味のある方はぜひダウンロードして手元でその効果を確認してほしい。
Parallel Composerを利用してソースコードをコンパイルParallel Studioをインストールすると、Visual Studioに各ツールに対応したツールバーが追加される(図3)。プログラムのコンパイルにParallel Composerに含まれるインテル C++ コンパイラーを利用するには、ツールバーの「Use Intel C++」ボタンをクリックすればよい(図4)。

コンパイラとしてインテル C++ コンパイラーを選択すると、プロジェクトのプロパティに設定項目が追加され、インテル C++ コンパイラー特有の最適化設定や並列化設定がGUIで行えるようになる。
今回、このようにしてParallel Composerで最大限の最適化設定(図5)でコンパイルしたプログラムと、Visual C++でコンパイルしたプログラムを比較したところ、Parallel Studioでコンパイルしたプログラムのほうが実行時間が短くなった。このようにParallel Composerを使用して単純にコンパイラを変更するだけでも、プログラムを高速化できることが分かる(表2)。
| 使用コンパイラ | 実行時間 |
|---|---|
| Parallel Studio(インテル C++ コンパイラー) | 1335ミリ秒 |
| Visual C++ | 1475ミリ秒 |
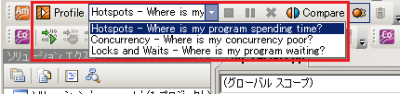
続いて、Parallel Amplifierを利用してプログラムのパフォーマンスを測定し、どの部分がボトルネックとなっているかを調査する。Parallel Amplifierを利用するには、Parallel Amplifierツールバーで調査する内容を選択し、「Profile」ボタンをクリックするだけだ(図6)
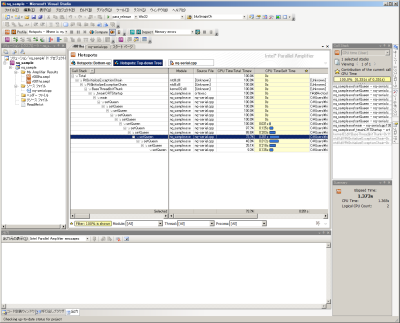
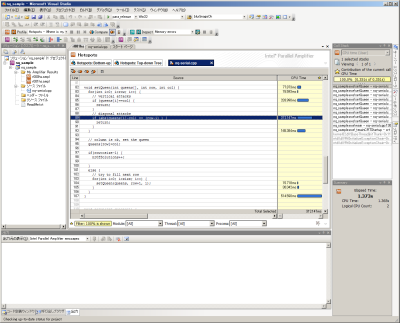
調査が完了すると、図7のように調査結果が表示される。図7ではプログラム中の関数が呼び出された順に表示されており、また一覧表示されている関数名をクリックすると、そのソースコードの詳細やそれぞれのステートメントの実行時間などを表示できる(図8)。これらより、今回の調査結果ではプログラム中のsetQueen()関数での処理が多くの時間を消費しているということが分かる。
続けて、Parallel Studioのインテル C++ コンパイラーが備える並列化キーワードを利用して、プログラムを並列化してみよう。今回はクイーンの数を求める「setQueen」関数を呼び出しているforループを並列実行することで、プログラムの並列化を行ってみる。
まず、並列化したいforループにインテル C++ コンパイラーの独自拡張キーワード「__par」を追加する。__parキーワードは、このキーワードを付加した部分を並列に実行するように指定するものだ。また、変数「queens」は探索に利用するための作業用バッファであるので、スレッドごとに独立してメモリを割り当てておく。
変更前:
void solve(int queens[]) {
for(int i=0; i<size; i++) {
// try all positions in first row
// create separate array for each recursion
setQueen(queens, 0, i);
}
}
変更後:
void solve() {
int* queens;
__par for(int i=0; i<size; i++) {
// try all positions in first row
// create separate array for each recursion
queens = new int[size];
setQueen(queens 0, i);
delete[] queens;
}
}
また、setQueens関数中ではグローバル変数「nrOfSolutions」の変更を行う個所があり、複数のスレッド間で同時にこの値を変更してしまうと問題が発生する。そこで、あるスレッドがこの変数に対する処理を行っている間は、ほかのスレッドから同じ処理を実行できないように「__critical」キーワードを追加する。
変更前:
if(row==size-1) {
nrOfSolutions++;
}
変更後:
if(row==size-1) {
__critical nrOfSolutions++;
}
これらの変更を加えたのち、再度プログラムをコンパイルしてパフォーマンスを比較したところ、次のように大幅な高速化が確認できた(表3)。
| 条件 | 実行時間 |
|---|---|
| 並列化前 | 1335ミリ秒 |
| 並列化後 | 758ミリ秒 |
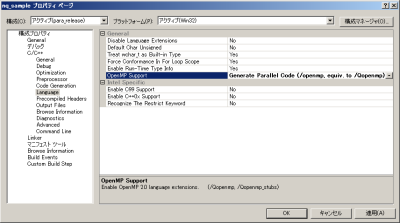
なお、__parや__criticalキーワードを利用したプログラムをコンパイルする際は、コンパイルオプションでOpenMPを利用するように設定しておく必要がある(図9)。
最後に、Parallel Inspectorを用いたバグの検出について紹介しておこう。今回のプログラムでは、__criticalキーワードを用いて複数のスレッドが同時にnrOfSolutions変数の値を変更することを防いでいる。そこで、今度はこのキーワードを付けずにプログラムをコンパイルし、エラーを検出させてみよう。
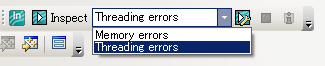
Parallel Inspectorを実行するには、Parallel Inspectorツールバーで検出するエラーを「Memory errors」もしくは「Threading errors」から選択して、「Inspect」ボタンをクリックし(図10)、続けて設定画面で分析レベルを指定する。今回はマルチスレッド処理に関する問題を検出したいので、分析する種類を「Threading Errors」とし、分析レベルは「Where are all the threading problems Inspector can find?」(スレッドに関わるすべての問題を対象にする)に設定した。
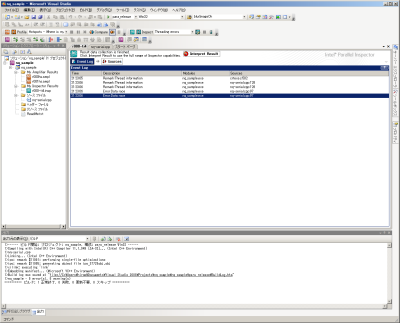
Parallel Inspectorによる分析が完了すると、まずどのようなイベントが検出されたのか、イベントログが表示される(図11)。ここでは、いくつかのデータ競合(Data race)が検出されているので、「Interpret Result」をクリックして検出結果の分析画面を表示させる(図12)。この画面では、画面上側に発生した問題が、下側に問題の詳細が表示される。この例では、nq-serial.cppの97行目、setQueen()関数内において、読み出しおよび書き込みについてのデータ競合が発生していることが分かる。
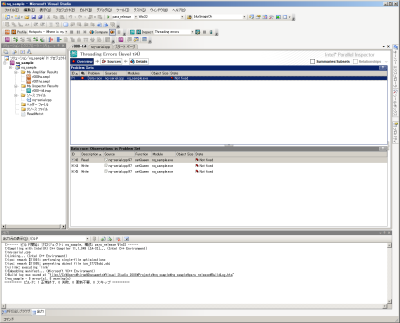
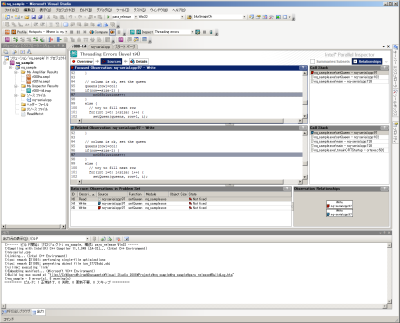
さらに、この画面で「Sources」をクリックするとソースコードの閲覧画面となり、競合の発生している個所のソースコードが表示される。これにより、先に__criticalキーワードを外した個所が競合の発生個所となっていることが分かる(図13)。
以上のようにParallel StudioはVisual Studioに統合され、非常に簡単にパフォーマンスの向上やパフォーマンスのボトルネック、問題点などを検出できる。これらのコンポーネントは、並列処理を利用しないプログラムにおいても有用なだけでなく、通常のデバッガではなかなか検出しにくいスレッド間の競合やデッドロックなども検出できるなど、マルチスレッドプログラムの開発に非常に役立つ。また、Parallel Composerで導入された新たなキーワードを利用することで、プログラムを比較的手軽に並列化することができる。マルチスレッドプログラムを開発している開発者や、パフォーマンスが必要なプログラムを開発する開発者にとって、Parallel Studioは非常に有用といえるだろう。