KDEの新しい検索フレームワークStrigiによるインデキシングと検索
Strigiでは各種プラグインを利用してインデックス、ファイルタイプ、メタデータ抽出の処理を行う。ファイルシステムのインデックス情報は、今のところSQLite 3、Xapian、CLucene、Hyper Estraierに保存できる。各種ファイルタイプ用のプラグインにより、PDFやオフィススイートのファイル形式など、プレーンテキスト以外のファイルからのテキストコンテンツの取得が可能である。また、メタデータ抽出用のプラグインにより、オーディオファイルのID3タグのようなファイルの付属情報も取得できる。
Strigiの配布パッケージには、メインとなるインデキシングデーモンstrigidaemonのほか、xmlindexer、strigiclient、strigicmd、deepfind、deepgrepといったクライアントが含まれている。strigiclientはGUIを備え、そこからstrigidaemonの起動と停止、インデックスの作成と検索が行える。
Fedora 8ユーザであれば、コマンド「yum install strigi」を実行してStrigiを標準のupdatesレポジトリから入手してインストールできる。
だが、今回試したRPM、「strigi-libs-0.5.7」はCLucene用のインデキシングに対応していなかった。これはかなり厄介な問題である。というのもStrigiはデフォルトでCLuceneを利用しようとするからだ。そのため、Strigiデーモンを起動しようとすると次のように致命的エラーが出る。
$ /usr/bin/strigidaemon Unknown backend type: clucene
今後のパッケージではぜひ修正してもらいたい問題だ。この問題を回避するために、CLucene、Qt4、exiv2の各開発パッケージをインストールし、Strigiをソースからビルドすることになった。Strigiでは、ビルド環境の設定にautotoolsではなくcmakeを使用する。Fedora 8の64ビットプラットフォームでビルドを行う際には、CLuceneを検出させるためにcmakeで「-D」オプションを指定する必要があることがわかった。以下のコマンド群を使えば、64ビット版Fedora 8マシンでStrigiをソースからインストールできる。
# rpm -e strigi strigi-libs # yum install clucene-core-devel qt4-devel cmake file-devel exiv2-devel ... $ tar xjvf .../strigi-0.5.7.tar.bz2 $ cd strigi-0.5.7 $ cmake -G "Unix Makefiles" -DLIB_SUFFIX=64 $ make ... [100%] Built target indextester [100%] Built target strigiclient $ sudo make install
Strigiにはデフォルトで、ファイルシステムの検索用として飾り気のないGUIクライアントが付属している。KDEやGNOMEを実行していれば、このstrigiappletを使ってデスクトップパネルからStrigiによる検索が行える。KDEユーザには、Konquerorから直接が検索が行えるKIOスレーブも用意されている。KIOスレーブおよびアプレットはstrigiappletパッケージに収録されているが、アプレットとKIOスレーブをビルドするにはkdebase-develとkdelibs-develをインストールする必要がある。
使い方
では、Strigiを使って、メタデータを抽出し、インデックスを作成して、検索を始める方法を見てみよう。Strigiがどのような情報を参照しているかを知るには、xmlindexerコマンドが役に立つ。あるファイルに対してxmlindexerを実行すると、そのファイルからインデキシングに使用される情報がStrigiによって抽出される。以下に、簡単なテキストファイルの例を示す。xmlindexerで絶対パスを指定すると、core#urlの値にそのファイルのフルパスが格納される。また、オーディオファイルに対してxmlindexerを実行すると、audio.title、audio.artist、audio.album、content.genreというメタデータが表示される。
[~]$ cd /tmp [tmp]$ date > testfile1.txt [tmp]$ xmlindexer testfile1.txt nthreads: 2 <?xml version='1.0' encoding='UTF-8'?> <metadata> <file uri='testfile1.txt' mtime='1200635133'> <value name='http://freedesktop.org/standards/xesam/1.0/core#url'>testfile1.txt</value> <value name='http://freedesktop.org/standards/xesam/1.0/core#size'>29</value> <value name='http://freedesktop.org/standards/xesam/1.0/core#sourceModified'>1200635133</value> <value name='http://strigi.sf.net/ontologies/0.9#depth'>0</value> <value name='http://freedesktop.org/standards/xesam/1.0/core#fileExtension'>txt</value> <value name='http://freedesktop.org/standards/xesam/1.0/core#name'>testfile1.txt</value> <value name='http://strigi.sf.net/ontologies/0.9#parentUrl'></value> <value name='http://strigi.sf.net/ontologies/0.9#depth'>0</value> <text>Fri Jan 18 15:45:33 EST 2008 </text> </file> </metadata>
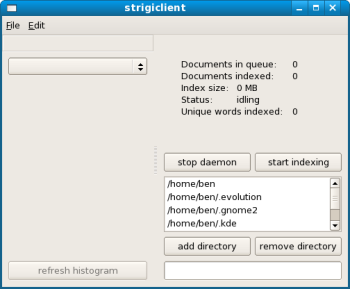
strigiclientコマンドを実行すると、右図のようなユーザインタフェースが現われる。編集メニューでは、フィルタの設定により、どのファイルがインデキシングの対象でどのファイルが対象外かを指定できる。各フィルタはファイル名に対するglob処理を利用しているため、ワイルドカードにマッチするファイルをインデキシングまたは無視するように指示できるわけだ。ワイルドカードとしては任意の文字列にマッチする「*」、任意の1文字にマッチする「?」が使える。詳細についてはmanページのglob(7)を参照してほしい。各フィルタは順に評価され、デフォルトではどのフィルタにもマッチしなかったファイルがインデキシングされる。また、インデキシングされた全ファイルの名前を編集メニューから一覧表示させることもできるはずだが、この機能は私の環境では動作していないようだった。
デーモン停止ボタンはトグル式になっており、Strigiデーモン起動/停止の操作が行える。また、GUIのディレクトリ追加/削除ボタンを使って、Strigiによるインデキシング対象ディレクトリを設定できる。検索を行うには、画面右下のフィールドに検索文字列を入力すればよい。
strigicmdプログラムを使えば、コマンドラインからStrigiインデックスの操作や検索が行える。コマンドラインから検索を行う場合は、実行したい本来のクエリに加えて、インデックスのタイプと場所を指定する必要がある。以下に示すクエリの最初の例は、指定したサイズにぴったり一致するファイルを探してくれる。2番目のクエリは、ファイル名に文字列“alice”が含まれるすべてのファイルを探し出す。その次は、「alice13a.txt」ファイルよりもあとに変更されたすべてのファイルを検索する例である。最後のクエリは、「alice13a.txt」の変更から24時間以内に変更されたファイルだけを検索するものだ。このようなクエリは、同じような時期に一連のファイルを変更したがそれらのファイルを正確に思い出せない場合に役立つ。ただ残念ながら、Strigiは人が理解できる時間の値を受け付けてはくれなかった。UNIXのtime_tによるエポック秒がそのまま利用されているためだ。
$ strigicmd query -t clucene -d ~/.strigi/clucene 'size=153477'
n backends: 1
Results for search "size=153477"
"/home/ben/guten/alice13a.txt" matched
- mimetype:
- sha1:
- size: 153477
- mtime: Sat Jan 12 13:23:59 2008
- fragment: - http://freedesktop.org/standards/xesam/1.0/core#fileExtension: txt
- http://freedesktop.org/standards/xesam/1.0/core#name: alice13a.txt
- http://strigi.sf.net/ontologies/0.9#depth: 0
- http://strigi.sf.net/ontologies/0.9#parentUrl: /home/ben/guten
Query "size=153477" returned 1 results
$ strigicmd query -t clucene -d ~/.strigi/clucene 'name:*alice*' \
| grep 'http://freedesktop.org/standards/xesam/1.0/core#name'
n backends: 2
- http://freedesktop.org/standards/xesam/1.0/core#name: alice13a.txt.desktop
- http://freedesktop.org/standards/xesam/1.0/core#name: alice13a.txt
- http://freedesktop.org/standards/xesam/1.0/core#name: alice13a.txt
- http://freedesktop.org/standards/xesam/1.0/core#name: alice-copy.txt
$ strigicmd query -t clucene -d ~/.strigi/clucene 'sourceModified>=1200108239' \
| grep 'http://freedesktop.org/standards/xesam/1.0/core#name'
n backends: 2
- fragment: - http://freedesktop.org/standards/xesam/1.0/core#name: konq_history
- http://freedesktop.org/standards/xesam/1.0/core#name: katepartindentjscriptrc
...
$ strigicmd query -t clucene -d ~/.strigi/clucene 'sourceModified>=1200108239 sourceModified<=1200194639|grep 'http://freedesktop.org/standards/xesam/1.0/core#name'
ファイル名またはその部分文字列でファイルを検索することもできる。サイズや名前のようなプレフィックスを指定しない場合は、以下の2番目の例に示すように、インデックスに対するフルテキスト検索が行われる。xmlindexerをファイルに対して実行すれば、クエリ内でどんなプレフィックスが使えるかがわかるだろう。
$ strigicmd query -t clucene -d ~/.strigi/clucene 'name:alice*'
n backends: 1
Results for search "name:alice*"
"/home/ben/guten/alice13a.txt" matched
- mimetype:
- sha1:
- size: 153477
- mtime: Sat Jan 12 13:23:59 2008
- fragment: - http://freedesktop.org/standards/xesam/1.0/core#fileExtension: txt
- http://freedesktop.org/standards/xesam/1.0/core#name: alice13a.txt
- http://strigi.sf.net/ontologies/0.9#depth: 0
- http://strigi.sf.net/ontologies/0.9#parentUrl: /home/ben/guten
Query "name:alice*" returned 1 results
$ strigicmd query -t clucene -d ~/.strigi/clucene 'mine'
...
Query "mine" returned 3 results
この段階で、“Wonderland”で検索をかけても小説“Alice in Wonderland”が見つからないことがわかった。これは、Project Gutenbergのサイトからダウンロードした小説の本文を「alice13a.txt」というファイルに保存したものだ。このファイルが見つからないということは、Strigiのフルテキスト検索で、本来見つかるはずのファイルがすべて見つかるとは限らないことを意味する。この不具合をデバッグするためにSQLite 3のStrigiバックエンドをビルドしたところ、「alice13a.txt」の情報がインデックスになっていないことがわかった。
Strigiがlibmagicを使っていること、その前のファイルインデキシングのコードは動作していたことから、何か意図があって「alice13a.txt」を無視しているのではないかと思った。libmagicライブラリは、ファイルタイプとファイルのMIMEタイプの検出に使われている。libmagicのコマンドラインツールにあたるのがfileである。「file -i」を実行してレポートされるMIMEタイプを確認すると、2つのファイルが「application/octet-stream」であるとのレポート出力が得られた。そのうちの1つが「alice13a.txt」だった。「alice13a.txt」のコピーを作成し、“Alice in Wonderland”という文字列を含む冒頭部だけを「alice-copy.txt」としたところ、fileコマンド(つまりlibmagic)はこれを間違いなくテキスト文書として認識してくれた。
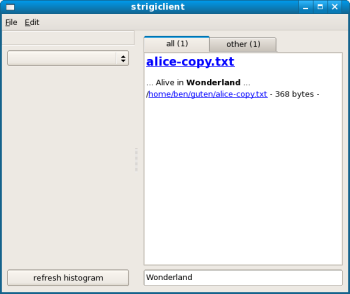
続いて、strigiclientの「start indexing(インデキシングの開始)」をクリックして、Strigiインデックスの更新を行った。そのあとで検索ウィジェットに「Wonderland」と入力すると、無事に「alice-copy.txt」を見つけ出すことができた(右図参照)。さまざまな文字エンコーディングがプレーンテキストの保存に使われる可能性がある場合、プレーンテキストファイルを確実に検索できることが課題になり得る。要するに私は、Project GutenburgのテキストがStrigiで無視されるとは予期していなかったのだ。
Strigiのdeepfindおよびdeepgrepコマンドでは、アーカイブファイルの中身まで検索できる。deepfindは、オプションのコマンドライン引数を1つしか取らない。このオプションは再帰的検索の起点を指定するもので、省略した場合はカレントディレクトリが起点になる。Strigiによって見つかった各ファイルのパスが1行ずつ表示される。deepfindが便利なのは、探すファイル名がわかっていてそのファイルのすべてのバージョンを見つけ出したい場合だ。しかもtar.gzファイル内にあるファイルも見つけてくれる。
deepgrepもdeepfindと同じようにアーカイブファイルの検索ができるが、標準のgrep(1)コマンドにより近い動作をする。だが、先週までにリリースされた多くのバージョンのdeepgrepには、まったく動作しないというバグがある。Strigiの次回リリースには修正版が収録される予定だ。deepgrepは次のように、必要な情報を含むアーカイブを、展開することなく探し出すのに役立つ。
$ deepgrep documentation /tmp/strigi-0.5.7.tar.bz2 /tmp/strigi-0.5.7.tar.bz2/strigi-0.5.7/cmake/FindQt4.cmake: # ask qmake for the documentation directory /tmp/strigi-0.5.7.tar.bz2/strigi-0.5.7/src/streamanalyzer/analyzerconfiguration.h: * TODO: write proper documentation of the pattern syntax. /tmp/strigi-0.5.7.tar.bz2/strigi-0.5.7/src/streamanalyzer/analyzerconfiguration.h: * See the documentation for the non-const version of this function. ...
Strigiによるインデックスへのファイルの追加は高速だが、完璧ではない。GUIの検索クライアントでは、一般的な検索の設定がもっと楽にできるようにしてほしい。たとえば、strigiappletでは検索文字列を入力できるが、どのフィールドをクエリに使用するかは選択できない。また、この検索クライアントが人が理解できる形式の時間文字列を解析できるようになれば、一定期間内に変更されたファイルの検索はもっと容易になるだろう。
全体として見れば、Strigiはファイルサイズ、ID3タグ、ファイル名のようなメタデータまたはテキストコンテンツによるファイル検索に便利なフレームワークだ。
Ben Martinはファイルシステムに10年以上携わっている。博士号を持ち、現在はファイルシステムのlibferrisと検索ソリューションに注力。