2つのデスクトップ検索ツールBeagleとTrackerの比較
どちらのツールもスタンドアローン形態で実行できるが、他のユーティリティに取り込まれる形で利用されているケースも多い。具体的にどのようなアプリケーションで利用されているかは、BeagleおよびTrackerの各Webサイトにて一覧されている。また各ディストリビューションパッケージにおけるBeagleのサポート状況によっては、過去にアクセスしたWebページをBeagleを使ってインデックス化するFirefox機能拡張が利用できるかもしれない。
これらツールの開発言語は、BeagleがMonoでありTrackerがCであるが、本稿では開発言語の優劣について深入りする気はない。開発言語の効率性やRAM使用量といった話題は1つのレビュー記事に収まりきる話ではないのも1つの理由だが、それ以前にツール全体としての総合評価は開発言語単体で決まるものではなく、この場合もCで記述されているからといってTrackerの方が優れているとは断言できないのである。
どちらのツールも、バックグラウンドでデーモンを実行してファイル群のインデックス化を進めるという点で共通している。つまりインデックス化対象のファイルシステムに変更が加えられるごとに、これらのデーモンがリアルタイムでインデックス情報をアップデートしていくのである。同じく、ユーザによるインデックス検索がRDFインタフェースで処理される点および、デフォルト設定下にて各自のhomeディレクトリがインデックス化対象とされる点も共通の仕様だ。またどちらのツールもマウントした外部接続型メディアをインデックス化できるが、Beagleの同梱されたディストリビューションによっては、そうした処理用のセットアップを施さなくてはならない。
デフォルト設定下のBeagleでは/usr/share/docといったパブリック扱いのディレクトリをインデックス化して当該システムの全ユーザにて共有するという、システムワイドな処理がされるようになっている。こうしたシステムワイドなインデックスとして何が利用可能かを確認したければ、beagle-info --list-static-indexesを実行すればいい。
BeagleはExtended Attributes(EA)を用いて、各ファイルごとのメタデータを格納している。EAを使用できない環境の場合はSQLiteデータベースを利用することもできるが、Beagle FAQの説明では「(SQLiteは)低速なためメインの格納先に使用すると、パフォーマンスが目に見えて低下します」と記載されている。Linuxカーネル2.6におけるEAはデフォルトでNFSをサポートしていないので、こうした制限は、NFSでマウントしたファイルシステムを扱う際に1つの障害となるかもしれない。BeagleのWebサイトにある説明では、NFSファイルシステムをエクスポートさせるサーバではスタティックインデックスを使用し、NFSでのファイルインデックス化に伴う「極度に遅いオペレーション」を回避することが推奨されている。
なお両プロジェクトのWebサイトを比較すると、Beagleの方がTrackerのサイトより内容が豊富で、例えばBeagleの設定と調整法に関する詳細な操作手順なども掲載されている。
インストールおよび各種の設定オプション
Beagleを入手するには、openSUSE 11用の1-Click Install、Ubuntu Hardy用のパッケージ、Fedora 9用の標準リポジトリのいずれかを利用すればいい。Trackerの場合は、FedoraおよびUbuntu Hardy用のリポジトリが利用でき、またopenSUSEのBuild Systemを探せば各種のパッケージが入手できるはずである。本稿を執筆する際に使用したのはFedora 9 x86_64インストレーションで、Beagleがバージョン0.3.7-4.fc9.x86_64、Trackerがバージョン0.6.6-2.fc9である。なおFedoraにてTrackerを使用する場合はtracker-search-toolパッケージもインストールしておくべきだろう。
どちらのツールにせよ通常の用途に供するのであれば、設定時に最大のポイントとなるのはインデックス化処理に関するプレファレンス指定であり、あるいは逆に、特定機能を実装した設定オプションの有無によってどちらのツールを使用すべきかを判断することになるかもしれない。ここでは参考用にプレファレンス設定画面のスクリーンショットを、Beagle(beagle-settings)およびTracker(tracker-preferences)別に掲載しておいた。
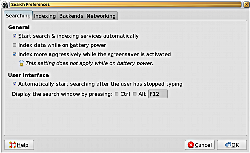
Beagleの場合、先に触れた“スタティックインデックス”をサポートしている。この方式でのスキャンは特定の状況下でのみ実施され、ファイルシステムの変更に応じたリアルタイムのアップデートは行われないのだが、設定ダイアログではこの機能に関する明示的なオプションは提示されていない。BeagleのWebサイトに掲載されている注意事項では、スタティックインデックスの非使用時におけるNFSのインデックス化作業が極端に低速化する点に言及されているというのに、その機能を設定画面にて有効化できないのでは片手落ちといわざるを得ないだろう。
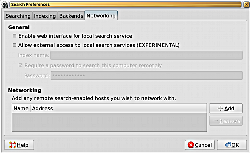
これと対照的に、ネットワークを介して他のBeagleインストレーションによる検索を実行する機能は、実験段階とされながらもBeagleの設定ダイアログにて提示されるようになっているのだが、残念ながらこの機能は実用数歩手前という完成度のようである。それと言うのも私の環境では、ネットワーク検索用にインデックス情報を公開するカスタムパスワードを設定することができず、そのまま強行的にインデックスの公開設定をしても検索可能なリモートホストとして認識されなかったのだ。あるいはこのダイアログは、ローカルホストにあるネットワークインタフェースは一律に排除するという仕様になっているのかもしれない。
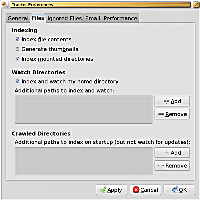
Trackerのプレファレンス設定では、バッテリ駆動時用の制御オプションが用意されている反面、スクリーンセーバ起動時に積極的なスキャンをするといったオプションは設けられていない。確かにこうした仕様に関しては、開発用の環境ではバックグラウンドでコンパイルを連続実行させるというケースもあるので、スクリーンセーバ起動中のシステムは必ずしもアイドルだとは言い切れないだろう。またTrackerの設定ダイアログでは、リアルタイムで変更をチェックさせるディレクトリ群および、スタートアップ時にのみスキャンさせるディレクトリ群(スタティックインデックス)を明示的に直接指定できるようになっている。
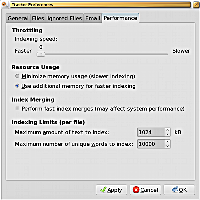
BeagleにはなくTrackerでは利用可能な設定オプションとしては、インデックス化するテキストサイズの指定およびファイルごとに収集するユニークな単語の最大数を指定するという機能が用意されている。どちらもデフォルトの設定値は控えめな値となっているが、例えば巨大なファイルシステムをインデックス化する際において、実際にはテキストファイルではないのにTrackerにはテキストだと認識される特殊なファイルがいくつか存在するような場合、ファイルごとの最大単語数を明示的に指定できる機能が役立つはずだ。もう一方のユニークな単語数の最大値指定は、インデックスの総単語数を最適化するというよりも、Trackerのインデックス化デーモンを長時間起動させ続けるファイルの出現を抑制させるための二次的な設定という意味合いが強いはずである。
今回私は、各ツールにおけるインデックス化のベンチマーク試験として、Linux Documentation Projectで公開されているHOWTOのテキストファイルをHTML(103MB)およびPDF(78MB)の両形式にて処理させてみた。どちらのツールもバックグラウンドにて動作するよう作られているため、Beagleのスタティックインデックス機能を例外とすると、特定ディレクトリのインデックス化処理に要する時間を正確に計測するのは簡単ではない。そこで今回の試験では、双方のデーモンを起動させてhomeディレクトリのコンテンツをインデックス化させた後、HTMLおよびPDFファイルを収めたディレクトリを個別に追加させることにした。その後ディレクトリの追加時刻を基にして、psコマンドにて表示されるタイムフィールドにてCPU使用率が大幅な増減を示し始めた時刻を確認することで、デーモンによるインデックス化処理に要した期間を算定するのである。
tracker-preferencesを用いて計測対象のディレクトリを登録するとトラッカデーモンが再起動されるので、タイムフィールドの差分計算をするには、デーモンが再度停止した後の時刻を確認すればいい。なお、デーモンの再起動からファイルのインデックス化開始までは若干のタイムラグが存在するが、psのタイムフィールド比較にこうした遅延分は介入しないので、ここでの最終的な計測結果には影響していないはずである。
デフォルト設定下のBeagleはTrackerに比べるとインデックス化速度をかなり抑制する仕様になっているようなので、今回はベンチマーク用の措置としてexport BEAGLE_EXERCISE_THE_DOG=1を用いてBeagleをフル速度で動作させるようにした。なおインデックス化処理の大半は、beagledでなくbeagled-helperプロセスにて費やされているようである。Trackerについては設定ダイアログのPerformanceページにて、ファイルのインデックス化速度を最大化させるオプションおよび、メモリを追加使用して高速処理させるオプションを有効化しておいた。
| デーモン | HTMLの所用時間 | PDFの所用時間 |
| (分:秒) | (分:秒) | |
| Tracker | 2:39 | 0:45 |
| Beagle | 2:45 | 1:18 |
こうしたファイル検索用にインデックス化される情報については、beagle-extract-contentおよびtracker-extractにてその詳細を確認することができる。その結果、少なくとも今回の試験に用いたPDFおよびHTMLファイルに関しては、TrackerツールよりBeagleツールの方が詳細な情報を収集していることが判明した。またtracker-extractの場合、任意の情報を収集させるにはmimetypeの指定をしなければならない。
$ tracker-extract /home/howto/pdf/Automount.pdf $ tracker-extract /home/howto/pdf/Automount.pdf application/pdf Doc:PageCount=9; Doc:Title=Automount mini-Howto; $ beagle-extract-content /home/howto/pdf/Automount.pdf Filter: Beagle.Filters.FilterPdf (determined in .29s) MimeType: application/pdf Properties: Timestamp = 2008-07-11 06:11:05 (Utc) beagle:FileType = document dc:appname = htmldoc 1.8.21 Copyright 1997-2002 Easy Software Products, All Rights Reserved. dc:title = Automount mini-Howto fixme:page-count = 9 Content: Automount mini Howto Automount mini Howto Table of Contents Automount mini Howto ........
英語以外のドキュメントを扱うユーザに関して補足すると、Trackerは複数言語にてステミング(語幹抽出)の処理をするmultilingual word stemmerに対応している。ここで言うword stemmerとは、派生語も検索できるように各単語の様々な変化形を基本形に戻す変換処理をするためのもので、例えば英語の動詞の末尾に付く“ing”を除去するなどの処理がステミングアルゴリズムの一環として実施されるのである。その他にTrackerではタグによる再検索も行えるよう、ファイルのタグ付け機能もサポートしており、特定ファイルに対するタグの追加、削除、リスト化は、コマンドラインからtracker-tagツールを実行することで簡単に処理できるようになっている。
まとめ
次回のレビューでは、両ツールにおける検索インタフェースおよび検索指定の方法について比較することにする。
最後に、私個人がこれらのツールと“競合”するlibferrisというオープンソース系のメタデータ抽出/インデックス化プロジェクトに参加していることを付け加えておかなくてはならない。もっとも、私はどちらのプロジェクトとも無関係な立場で活動しているのであり、本稿におけるTrackerおよびBeagleに対するレビューも公平な視点で行ったつもりである。なおKDEユーザの場合は、インデックス化方式の検索ツールとしてStrigiを使うという選択肢を検討してもいいだろう。
Ben Martinは10年以上にわたってファイルシステムに取り組んでおり、博士課程の修了後、現在はlibferris、ファイルシステム、検索ソリューションを中心としたコンサルティング業に従事している。