VTune Amplifier XEとInspector XEでmemcachedの高速化にチャレンジ 4ページ
解析結果を確認する
VTune Amplifier XEでの解析結果概要は「Summary」タブ内に表示されるので、まずはここを確認する(図15)。ここで注目したいのが、「Top Hotspots」の部分だ。ここでは実行中に時間のかかった関数が順に表示される。
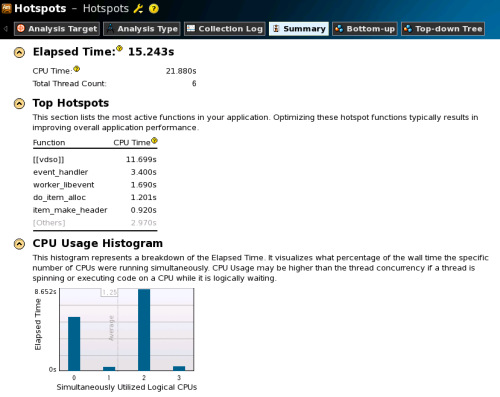
ここでもっとも時間がかかっていたのは、「[[vdso]]」の11.699秒である。この「[[vdso]]」は、「VDSO(Dynamic SHared Object」と呼ばれる仕組みを用いて実行されたLinuxカーネル命令を意味している。つまり、memcachedではLinuxカーネル命令を実行している時間がもっとも多い、ということだ。そして、次に時間がかかっている個所が「event_handler」という関数である。この関数について詳細にチェックするには、まず「Bottom-up」タブを選択して関数一覧を表示させる(図16)。
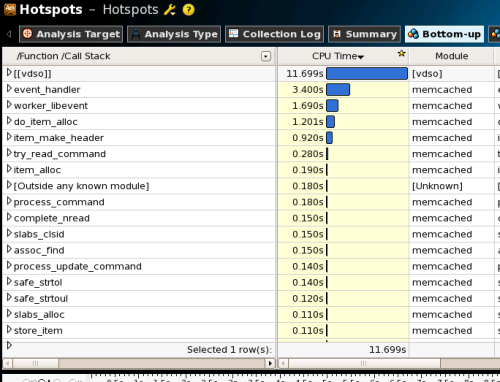
続けて「event_handler」をダブルクリックすると、該当のソースコードが表示される(図17)。
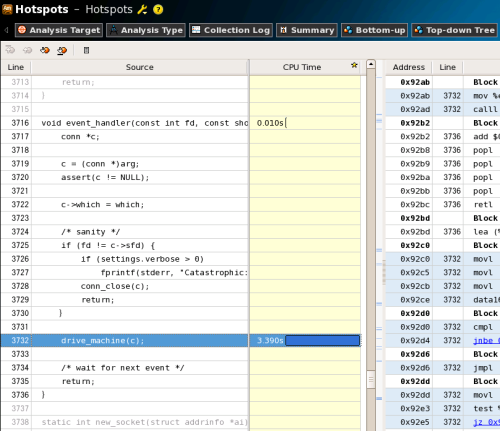
さて、ここではevent_handler内の「drive_machine」関数の実行に時間がかかっていることが分かるのだが、この関数内のどこで時間がかかっているのかは表示されない。これは、この関数がコンパイラによってインライン展開されているためだ。VTune Amplifier XE内でこの関数に対応するアセンブラコードは表示されるものの、このままではより詳しい解析が難しい。そこで、ソースコードに手を加えてこの関数をインライン展開しないよう指定し、再度VTune Amplifier XEを実行することにする。
該当の関数は、memcachedのmemcached.c内で次のように宣言されている。
static void drive_machine(conn *c); static int new_socket(struct addrinfo *ai); static int try_read_command(conn *c);
GCCではこの宣言部分に「__attribute__((noinline))」というキーワードを付けることで、その関数をインライン展開しないように指定できる。修正後のコードは次のようになる。
static void drive_machine(conn *c) __attribute__((noinline)); static int new_socket(struct addrinfo *ai); static int try_read_command(conn *c);
このようにソースコードを変更した後、再コンパイルを行って再度VTune Amplifier XEを実行した結果は次の図18のようになる。今度はインライン化を抑制したdrive_machine関数が、[[vdso]]に次ぐ時間のかかる処理となっていることが分かる。
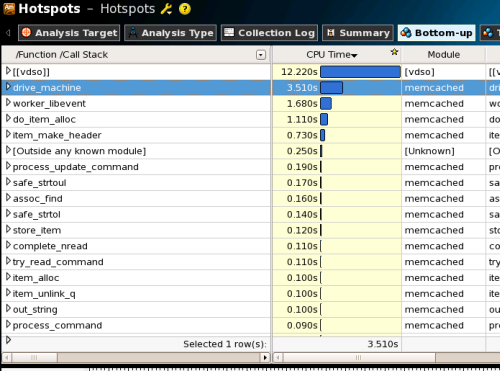
さらに、drive_machine関数に注目してみると353行目の「memmove」関数呼び出しにもっとも時間がかかっていることも確認できる(図19)。
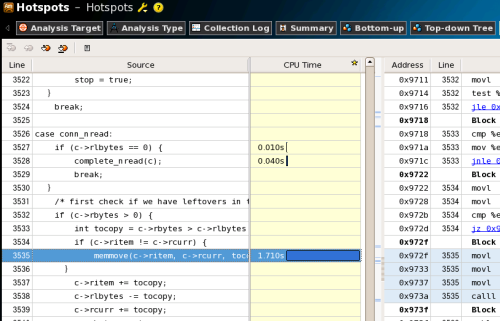
さて、以上の結果、memcachedの実行時間の大半はLinuxカーネルのAPI実行で、次にメモリ関連の処理、ということが分かった。このような場合、簡単なコード修正でパフォーマンスを向上させるのは難しい。そこで、インテル C++ Composer XEを使用してmemcachedをコンパイルし、コンパイラによる最適化でのパフォーマンス向上が見られないかを検証した。インテル C++ Composer XEには、インテル独自のライブラリを使用してC/C++標準関数を高速化するオプション「-use-intel-optimized-headers」が用意されている。これを利用してmemcachedをコンパイルし、VTune Amplifier XEを用いて再度パフォーマンスを測定してみた。
なお、コンパイルの際に使用したconfigureオプションは次のようになる。
$ ../configure CC=icc LINK=xild "CFLAGS=-O3 -ipo -g -use-intel-optimized-headers" "CXXFLAGS=-O3 -ipo -g -use-intel-optimized-headers"
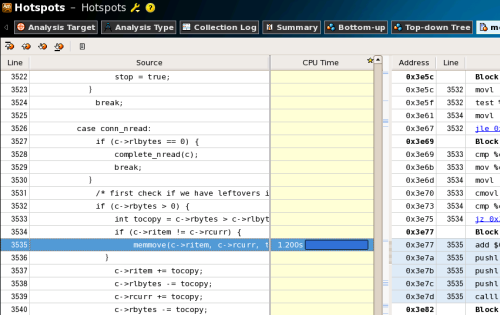
このようにしてインテル C++ Composer XEを用いてコンパイルしたmemcachedに対し、同一の条件でVTune Amplifier XEによるプロファイリングを行った結果の「drive_machine」関数部分が次の図20だ。GCCでコンパイルした際には1.710秒だったmemmove関数の実行時間が、インテル C++ Composer XEによるコンパイルでは1.200秒に短縮されていることが分かる。
また、GCCでコンパイルしたmemcachedと、上記のコンパイルオプション付きでインテル C++ Composer XEでコンパイルしたmemcachedとでのスループットの差は次の表3のようになった。ここでは、約4%程度の性能向上が確認できる。
| 使用したコンパイラ | GCC 4.1.2 | インテル C++ Composer XE 2011 |
|---|---|---|
| コンパイルオプション | -O2 -g | -O3 -ipo -g -use-intel-optimized-headers |
| スループット(コマンド/秒) | 54141.0 | 56575.5 |
このようにVTune Amplifier XE 2011を利用すれば、非常に手軽にパフォーマンス解析が可能となる。また分かりやすいGUIで結果が表示され、パフォーマンス解析に慣れていないユーザーでも分かりやすく結果を確認できるのも魅力の1つと言えるだろう。
パフォーマンス改善だけでなくプログラムのデバッグや解析にも有用なインテル Parallel Studio XE 2011
以上、簡単ではあるがParallel Studio XEを用いてmemcachedのパフォーマンス解析やチューニングを試みる例を紹介した。インテルの開発ツールというと数値計算を多用する工学/科学分野やマルチメディア処理向け、という印象を持っている方もいるかもしれない。しかし今回紹介した例のように、一般的な分野においてもデバッグやパフォーマンス解析においてParallel Studio XEは非常に有用なツールとなる。
また、ここではシンプルなテストしか行っていないが、memcachedに与えるリクエストの種類やデータサイズをさまざまに変更することで、また異なる結果が出る可能性は多いにある。memcachedのチューニングに興味のある方はParallel Studio XEの無償体験版を利用し、お使いの環境でコンパイルオプションや負荷のかけ方などを変えながらの実践的なチューニングにチャレンジしてみてはいかがだろうか。