VTune Amplifier XEとInspector XEでmemcachedの高速化にチャレンジ
ソフトウェア開発において、テストやデバッグは設計やコーディング以上に重要な工程である。これらの工程において、プログラム中の問題検出やパフォーマンス解析に役立つ強力なツールがインテル Parallel Studio XEに含まれる「インテル VTune Amplifier XE」や「インテル Inspector XE」だ。本記事ではこれらのツールを用いてmemcachedのチューニングを行い、高速化を試みた事例を紹介する。
プログラム解析に役立つ「インテル VTune Amplifier XE」と「インテル Inspector XE」
ソフトウェア開発工程においては、一般に設計→実装→テスト、という順序で開発が進められる。一般にソフトウェア開発というと、実際にプログラミングを行う実装工程が注目されがちではあるが、そのあとに行われるテストも非常に重要な工程であり、実装工程以上に時間やコストを要することも少なくない。
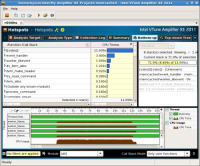
一般的なソフトウェアのテスト工程では、プログラム中にバグがないか、また必要となるパフォーマンスを満たしているかなどの検証や分析が行われる。これらの作業を支援する強力なツールが、インテルの最新開発ツールスイート「インテル Parallel Studio XE 2011」(以下、Parallel Studio XE)に含まれる「インテル Inspector XE 2011」(以下、Inspector XE)と「インテル VTune Amplifier XE 2011」(以下、VTune Amplifier XE)だ(図1、2)。
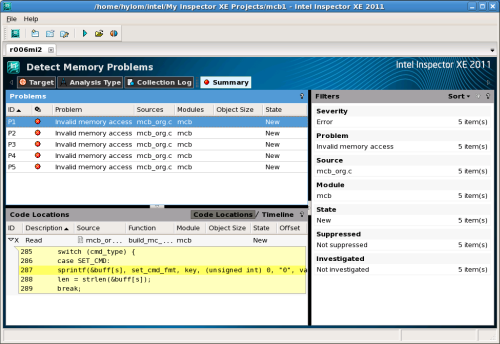
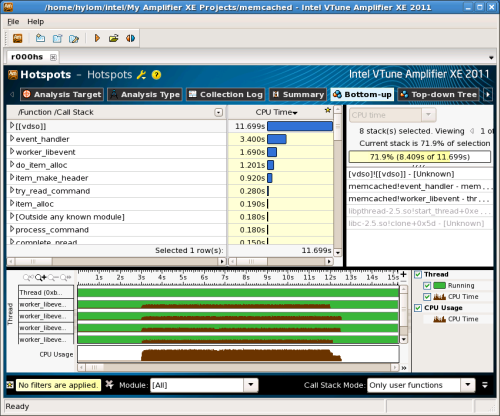
Inspector XEはメモリリークや不適切なメモリアクセスといったメモリ関連の問題や、デッドロックやメモリアクセスの競合といったマルチスレッドプログラムにおける問題を解析・検出するツールである。また、VTune Amplifier XEはプログラムの動きを計測し、実行に時間がかかっている個所やその原因などを表示するツールだ。
これらのツールはさまざまな分野のアプリケーション開発で役立つが、特に有用な分野の1つとして、高パフォーマンスが要求されるサーバーソフトウェア開発が挙げられる。このようなソフトウェアではパフォーマンスを向上させるためのチューニングが必要であり、また多くのリクエストを処理するための複雑なコードは想定外の問題を生みやすい。このような状況において、Inspector XEやVTune Amplifier XEは活躍する。
以下では、実際にParallel Studio XEが有用だった事例として、「memcached」のパフォーマンス解析とチューニングを紹介する。memcachedはオープンソースのキャッシュシステムで、キーと値のペアを格納し、リクエストに応じてキーから対応する値を取り出すといった「Key-Valueストア」と呼ばれるシステムの1つだ。memcachedはWebアプリケーションの分野で非常に多く用いられており、mixiやTwitter、Flicker、Slashdotなど大手サイトでも利用されているため、その名前を聞いたことがある人も多いだろう。
memcachedは揮発性のキャッシュシステムであり、ディスクなどのストレージにはデータを保存せず、データはすべてメモリ内に格納される。そのため、実行される処理はリクエストのパースやメモリアクセスなどが大多数を占めていると予想できる。これらの処理がチューニングによって改善できるのか、また改善できる場合どのような対処を行えばパフォーマンス向上が期待できるのか、を調べることが解析の目的となる。
なお、memcachedはさまざまなOS環境で動作するが、今回はLinux環境での利用を想定して解析を行った。解析にはLinux版のParallel Studio XEを使用している。
メモリ関連の問題検出に有用なInspector XE
プログラムのチューニングを行う際にまず検討すべきなのが、プログラムのパフォーマンス測定方法だ。外部からのリクエストを受けて処理を実行するサーバープログラムの場合、なんらかの手段でサーバーに十分な負荷を与えるようなリクエストを発行する必要がある。memcachedの場合、大量のリクエストを発行してその処理時間を測定するベンチマークソフトウェアがいくつか公開されている。今回はその1つである「mcb」を用いて、パフォーマンス解析を行うこととした。
mcbは複数のスレッドを用いて連続してmemcachedにリクエストを送信し、memcachedがそれらのリクエストを処理するのにかかった時間を測定するプログラムである。ところが、筆者がこのプログラムの「version 1.0 rc2」を用いてmemcachedのベンチマークを行おうとしたところ、特定のパラメータを与えた場合のみ高確率でセグメンテーションフォールトが発生する、という問題が発生したのである。
mcbはオプションでベンチマークの条件を変更可能で、たとえば「-t」オプションで同時にアクセスを行うスレッド数を、「-n」オプションでmemcachedに対して発行するコマンド数を指定できる(表1)のだが、この「-n」オプションに与える値を6000以上に設定するとセグメンテーションフォールトが発生することがあり、またこの値を大きくするほど高頻度でセグメンテーションフォールトが発生する、という現象が確認できた(リスト1)。
| オプション | 説明 |
|---|---|
| -c <コマンド> | 発行するコマンドを指定する。「set」および「add」、「get」が指定できる |
| -a <IPアドレス> | 接続するmemcachedが動いているマシンのIPアドレスを指定する |
| -t <スレッド数> | 同時に実行するスレッド数を指定する |
| -n <コマンド数> | 発行するコマンド数を指定する |
| -l <データサイズ> | リクエストとともに送信するデータサイズの平均値を指定する |
リスト1 mcbの実行例
$ ./memcached -m 1024m & ←memcachedを実行
$ ./mcb -c set -t 2 -n 10000 ←ベンチマークを実行:エラー終了
*** glibc detected *** ./mcb: free(): invalid next size (normal): 0x09fcc1f0 ***
======= Backtrace: =========
/lib/libc.so.6[0xbff5a5]
/lib/libc.so.6(cfree+0x59)[0xbff9e9]
./mcb[0x8049da0]
/lib/libpthread.so.0[0xd28832]
/lib/libc.so.6(clone+0x5e)[0xc67f6e]
======= Memory map: ========
00249000-0024a000 r-xp 00249000 00:00 0 [vdso]
00b72000-00b8d000 r-xp 00000000 03:03 1639306 /lib/ld-2.5.so
:
:
bf8c9000-bf8de000 rw-p bffe9000 00:00 0 [stack]
アボートしました
$ ./mcb -c set -t 2 -n 10000 ←同じコマンドを実行:今度は成功
condition =>
connect to 127.0.0.1 TCP port 11211
command = set
2 thread run
send 10000 command a thread, total 20000 command
data length = 1024
result =>
interval = 0.377967 [sec]
performance = 52914.689133 [command/sec]
thread info:
ave. = 0.377855[sec], min = 0.377829[sec], max = 0.377881[sec]
$ ./mcb -c set -t 2 -n 10000 ←同じコマンドを実行:今度はセグメンテーション違反でエラー終了
セグメンテーション違反です
このように「確実には発生しないが、何回か実行するとある程度の割合で発生する」というな問題はデバッグが難しい。そこで問題を追求するため、Inspector XEを使用してデバッグを行うこととした。