VTune Amplifier XEとInspector XEでmemcachedの高速化にチャレンジ 2ページ
インテル Inspector XEによる問題検出
インテル Inspector XEでプログラムを解析する場合、デバッグ情報をバイナリに埋め込む「-g」オプションを付けてコンパイルを行う必要がある。mcbは単一のソースファイルのみで構成されており、今回は次のようにコンパイルを行った。
$ gcc -o mcb -lpthread -g mcb.c
コンパイルに成功したら、続けてInspector XEを起動してコマンドラインオプションなどを設定する。Inspector XEは「/opt/intel/inspector_xe_2011/bin32/」以下の「inspxe-gui」コマンドを実行することで起動できる。通常このディレクトリにはパスは通っていないので、明示的にパスを設定するか、次のようにフルパスで実行する必要がある。
$ /opt/intel/inspector_xe_2011/bin32/inspxe-gui &
Inspector XEのGUIを起動すると、図3のようにスタートアップ画面が表示される。Inspector XEでは「プロジェクト」という単位で各種設定などを一括管理するので、まずは新たなプロジェクトを作成する。
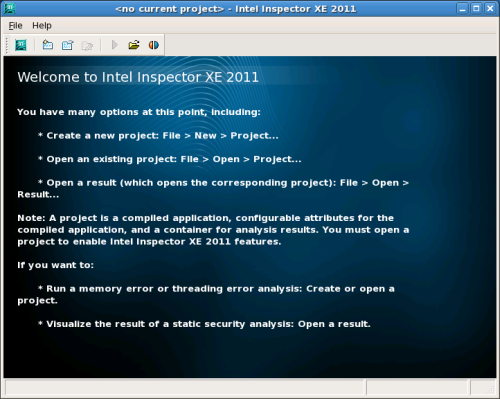
「File」メニューの「New」-「Project」を選択すると「Create Project」ダイアログが表示されるので、プロジェクトのディレクトリ名および作成場所を指定し、「Create Project」をクリックする(図4)。
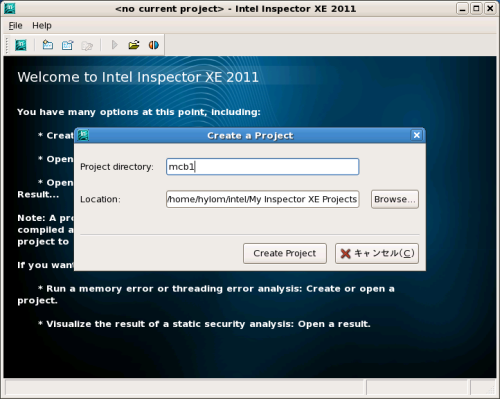
続けて対象となるプログラムを起動するためのコマンドラインやそのオプション、作業ディレクトリなどを設定する画面が表示されるので、これらを指定して「OK」をクリックすればプロジェクトの作成が完了する(図5)。
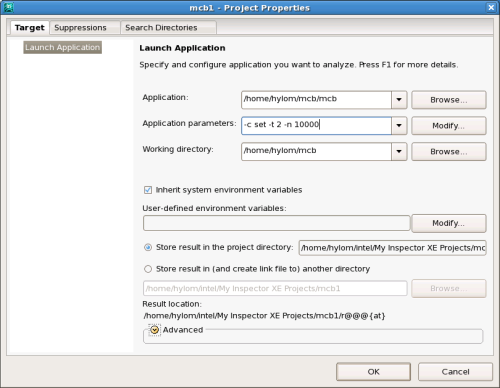
プロジェクトの作成後、ツールバーの「New Analysis Result」ボタンをクリックすると解析オプションを指定する画面が表示される(図6)。今回はメモリ関連のエラーを調査することが目的なので、「Memory Error Analysis」中の「Detect Memory Problems」を選択し、画面右側の「Start」ボタンをクリックすると解析が開始される。
プログラムが実行され、解析が完了するとその結果がウィンドウ内に表示される(図7)。
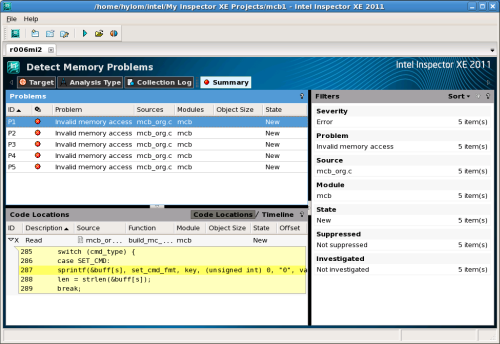
不正なメモリアクセスを確認する
さて、上記のようにInspector XEを実行したところ、次のリスト2、3の個所で計4つのメモリエラーが検出された。
リスト2 問題のあるメモリアクセスが検出された個所1
static int
build_mc_cmd(char *buff, const int buff_size, const int cmd_type,
const int key, const char *val,
const size_t val_len, const unsigned long int id)
{
int len = -1;
int s;
memset(buff, 0, buff_size);
s = (sysval.type == UDP) ? 8 : 0;
switch (cmd_type) {
case SET_CMD:
↓メモリ読み出しエラー発生
sprintf(&buff[s], set_cmd_fmt, key, (unsigned int) 0, "0", val_len, val);
:
(以下略)
:
リスト3 問題のあるメモリアクセスが検出された個所2
static void connector_thread(void *arg)
{
const int no = (int) arg;
int fd;
int i, j, len, str_len;
unsigned long int id;
char *buff, *data;
:
(中略)
:
if ((buff = calloc(1, sysval.data_len * 2 + 100)) == NULL) { ……(1)
elog("calloc error");
exit(-1);
}
if ((data = calloc(1, sysval.data_len * 2 + 1)) == NULL) {
elog("calloc error");
exit(-1);
}
memset(data, 67, (size_t) sysval.data_len * 2); /* char'67' = 'C' */
data[sysval.data_len * 2] = '\0';
:
(中略)
:
for (i = 0; i < sysval.command_num; i++) {
:
(中略)
:
j = 1 + (int) ((double) sysval.max_key * rand() / (RAND_MAX + 1.0));
↓メモリ読み出しエラー発生 ……(2)
str_len = 1 + (int)((double)strlen(data) * rand() / (RAND_MAX + 1.0));
data[str_len] = '\0'; ←メモリ書き込みエラー発生 ……(3)
↓メモリ読み出しエラー発生
len = build_mc_cmd(buff, sizeof(buff), sysval.command, j, data, strlen(data), id);
data[str_len] = 'a'; ←メモリ書き込みエラー発生 ……(4)
do_cmd(fd, buff, len, id);
if (sysval.single_command == true && sysval.type != UDP) {
len = build_mc_cmd(buff, sizeof(buff), QUIT_CMD, 0, NULL, 0, id);
do_cmd(fd, buff, len, id);
do_close(fd);
}
:
(中略)
:
}
検出結果を確認すると、これらの個所ではすべてポインタ「data」で指示されるメモリ領域に対してアクセスを行っていることが分かる。dataポインタはローカル変数であり、リスト2内のconnector_thread関数内のみで使用されている(関数の始めでメモリ領域が確保され、関数の最後で開放されている)。dataへの書き込みはconnector_thread()関数内でのみ行われているため、この関数内で何か不正なメモリアクセスが行われている、ということが推測できる。
さて、以上をふまえてソースコード中の対象となる個所を確認すると、2つの問題があることに気付く。まず1つめは、build_mc_cmd関数の第2引数で与えている「sizeof(buff)」という個所である。build_mc_cmd関数の第2引数はバッファとして使用するメモリ領域のサイズを与えるものだが、「sizeof(buff)」という指定ではbuffポインタが示すメモリ領域のサイズではなく、buffポインタのサイズである「4」(32ビット=4バイト)を返してしまう。本来はメモリ割り当て時(リスト2の(1))に指定したサイズである「sysval.data_len*2+100」を指定すべきである。
そして2つめが、(2)の個所である。ここでは「1以上strlen(data)以下」のランダムな整数値を生成してstr_len変数に格納し、続けてdata[str_len]にNULLをセットする、という処理を行っている(図8)。これはランダムな長さの文字列を生成する処理に相当する。生成した文字列はbuild_mc_cmd関数の引数として与えられた後、(4)の部分で再度NULLがあった個所に別の値を書き込むことで、バッファを復元している。ここで問題となるのが、str_lenの値がstrlen(data)と等しくなった場合である。
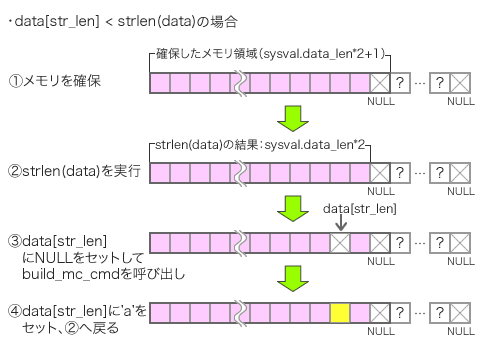
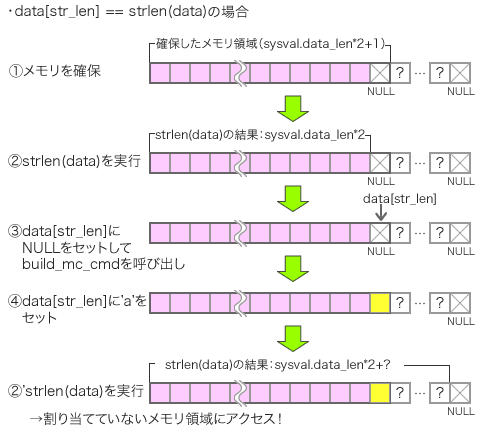
図9を見ていただければ分かると思うが、「str_len == strlen(data)」となる場合、確保したメモリ領域の末尾をNULLから「a」に書き換えることになる。この部分の処理はforループ内にあり、同じ領域に対して何度も処理が繰り返されるわけだが、この場合続けて実行されるstrlenが確保しているメモリ領域外にアクセスを行い、不正な値を返してしまう。
この問題はrand()で生成される乱数が特定の値の場合にのみ発生し、その確率はstrlen(data)、つまりdataバッファのサイズによって変わる。たとえばdataバッファのサイズが1024の場合、問題が発生する確率は約1000分の1程度となる。しかし、この処理は「-n」オプションで指定した回数分だけ繰り返されるため、「-n」オプションに大きい値を指定すると問題が発生する確率が高くなるのである。
この問題の解決方法はいくつかあるが、もっとも分かりやすいのは(4)の部分を次のように修正することだろう。
if (str_len != sysval.data_len * 2)
data[str_len] = 'a';
このようにすれば、data[str_len]がメモリ領域末尾のNULLを上書きしてしまうことを回避できる。
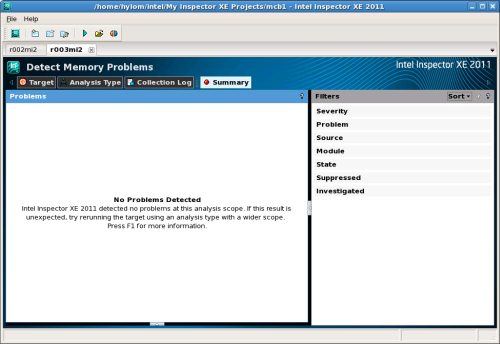
以上の2点の修正をコードに加えた結果、mcbの実行時にセグメンテーションフォールトを発生させることはなくなり、またInspector XEで解析を行っても問題点は検出されなくなった(図10)。
C/C++プログラミングにおいて、メモリ管理に関連する問題は比較的発生しやすい。たとえばセキュリティホールの原因としてよく挙げられるバッファオーバーフローは、確保していたメモリ領域を越えた位置にデータを書き込もうとして発生する。「バッファオーバーフローによる脆弱性が見つかる」というニュースが珍しくないことからも分かるとおり、熟練した開発者であっても効率良く確実にメモリの不正なアクセスを見つけることは難しい。さらに今回のように、発生の要因にランダム性があるバグは通常のデバッガでは検出や原因個所の特定が難しい。このような問題に対処するのに、Inspector XEは非常に有用なツールだといえるだろう。