Parallel Studioを活用したソフトウェアの並列化:AACエンコーダを高速化する 4ページ
OpenMPによる並列処理の実装
Parallel Amplifierの実行結果より、wav_read_float32()関数やrfft()関数、FixNoise()関数、AACQuantize()関数などについて何らかの並列化を行えばよい、という指針が得られた。そこで、これらの関数を呼び出している関数に対して、並列化できる個所がないかを探して行くこととなる。
ここでソースコードを分析してみると、fft_proc()関数は「PsyBufferUpdate()」関数から呼ばれており、FixNoise()関数は「AACQuantize()」関数、QuantizeBand()はFixNosie()関数内で呼び出されていることが分かった。さらに、PsyBufferUpdate()およびAACQuantize()関数はfaacEncEncode()関数内で呼び出されている(図10)。つまり、faac内では多数のループが呼びされているのだが、faacEncEncode()関数はこれらのループのうちもっとも外側で呼びだされているのである。
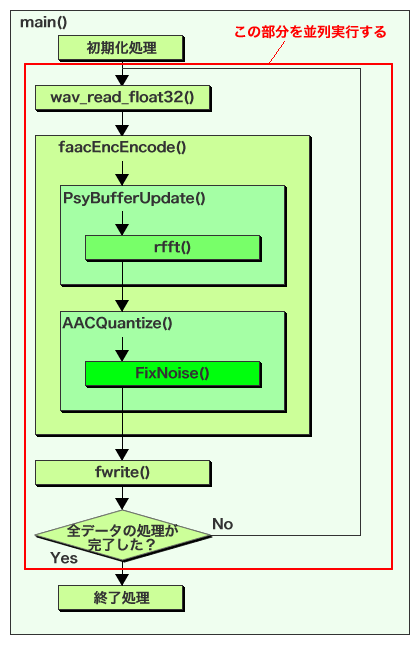
そこで、まずはaacEncEncode()の実行を並列化し、複数のスレッドで同時実行する方針で実装を行うことにする。faacのエンコーダ部はスレッドセーフな実装になっているので、複数のエンコーダを用意し、読み込んだデータを並列にエンコードして読み込んだ順に出力する、という流れである。
詳細については記事末のソースコードを参照してほしいが、変更を加えた点を簡単にまとめると下記のようになる。
- エンコーダのインスタンスを複数用意
- 処理のメインループを複数のスレッドで同時処理
- 入力データは読み出した順にシーケンスIDを付け、エンコード後はシーケンスIDの順番にデータを出力
このような並列化を行ったところ、先ほどと同じテスト環境(表2)では実行時間が約50%削減できることが確認できた(表3)。
| ソースコード | コンパイラ | 実行時間 |
|---|---|---|
| オリジナルfaac | Visual C++ | 10.7秒 |
| インテル コンパイラー | 8.8秒 | |
| 並列化版faac | Visual C++ | 5.3秒 |
| インテル コンパイラー | 4.6秒 |