第7回 The Linux Foundation Japan Symposium 講演録
ドライバ・バックポートの標準化に向けて

最初にNovellのSusanne Oberhauser氏から「LF Driver Backports & Distribution workgroup」と題された講演が行われた。Driver Backports & Distribution workgroupは、その名の通りドライバのバックポートと配布方法を改善するためにLinux Foundationに設置されたワーキンググループであり、現在はディストリビューター(Novell、Red Hat、Canonical)とシステムベンダー(富士通・シーメンス、IBM、Dell、HP)が参画している。同ワーキンググループは最近活動を始めたばかりでまだ具体的な成果を出していないが、氏の講演ではドライバのバックポートに関してどのような問題が存在し、それをどのように改善すべきかが語られた。
Linuxカーネルはバージョンアップのたびに新しいドライバを取り込んでいるが、新しいドライバを既存のディストリビューションで利用するためには、ドライバをバックポートする必要がある。現在認識されている問題とは、ドライバのバックポートとバックポートしたドライバの配布がコンポーネントベンダー(ドライバ開発者)やシステムベンダー、ディストリビューターごとに行われていて、それぞれが十分に連携できていないこと。そして、関係者間のインタフェースが整理されておらず「“うどん”のような状態」になっていることだという(Oberhauser氏は今回の来日で初めてうどんを食べたそうである)。こうした状況はエンドユーザーを混乱させるだけでなく、トラブルが発生した際に十分なサポートが得られないという状況を生み出している。 そこでDriver Backports & Distribution workgroupでは、この問題を解消するためのドライバのバックポートと配布に関する標準プロセスを確立しようとしているそうだ。ただし新しいドライバと言っても、その利用形態は新しいデバイスを既存システムに追加するケースもあれば、既存のドライバを新しい修正版で置き換えるケース、新しいサーバで既存のディストリビューションを利用するケースなどさまざまであるため、それぞれのケースごとに配布方法を標準化する必要がある。同ワーキンググループでは、ケースごとの要件を整理して、今年7月開催のOttawa Linux Symposium 2008に間に合うようにホワイトペーパーを作成・公開する考えだ。そして将来的には、Linuxの標準仕様であるLSB(Linux Standard Base)にドライババックポートに関する要項を盛り込み、ドライバの標準配布プロセスがLSB準拠のディストリビューションで機能するようにしたいとのことである。 続いてSGIのChristoph Lameter氏から、Linuxのメモリ管理機構(VM)に関する現状と問題点についての講演「Memory Management Under Linux: Issue in Linux VM development」が行われた。 講演の冒頭でLameter氏は「Linuxのメモリ管理における普遍的な課題は、システムのプロセッサ数とメモリ容量が増大するにつれて、VMがどんどん複雑化しつつあることであり、個人的にここ1、2年の問題として心配しているのはページサイズが4KBのx86_64のシステムにおいて10億オーダーものページ群を管理しなければならないことだ」と述べた。ちなみにx86_64における問題は64KBページを導入することで解消でき、そのためのパッチもすでに存在するそうである。ただし、そのパッチがカーネルに取り込まれて実際の運用現場で利用できる状態になるまでは、現在の仕組みで持ちこたえなければならないとのことである。 続けてLinuxのVMのコンポーネント構成について簡単に解説したあと、Lameter氏は以下のようなLinuxにおけるメモリ管理の原則を紹介した。 こうしたメモリ管理についての基本的なガイダンスをしたあとでLameter氏は、最近VMに取り込まれた新機能を解説した。解説された機能には以下のようなものがある。 このあとLameter氏は、まだカーネルに取り込まれていないもののすでに解決策が存在する問題(冒頭のx86_64のページサイズの問題など)と対策が講じられつつある問題、認識はされているが手つかずの状態にある問題(デバイスやサブシステムによるメモリピンニングの問題など)について説明した。例えば、デバイスやサブシステムによってメモリのピンダウンが生じるといった問題にはこれといった有効な対策がないとのことである。 氏の講演ではさまざまな問題が指摘されたため、Linuxが問題だらけであるような印象を受けなくもない。だが、その多くは例えば大規模NUMAシステムにおいてのみ発現するような局所的な問題であり、しかも大抵はパフォーマンスが十分にスケールしないなどといった類の問題であってシステムが機能不全に陥るような致命的なものはなかったようである。問題によってはアプローチの異なる複数の改善案が提出されているものもあり、「LinuxのVM周りでハイレベルなチューニングが続けられている」というのがLameter氏の講演から抱いた感想である。 昼の休憩後に再開された講演では、まず、Linux-HAプロジェクトの創始者でありリーダーであるIBMのAlan Robertson氏から、Linux-HAを紹介「World Class HA with Linux-HA」が行われた。 Robertson氏はHAクラスタにおける基本的な仕組みを解説したあとで、話題をLinux-HAに移した。Linux-HAは、Heartbeatを中核コンポーネントとするHAクラスタウェアであり、Heartbeatはシングルシステムにおけるinitプロセスと同じような機能をクラスタに対して提供する。また、Linux-HAは特別なハードウェアを必要とせず、ユーザースペースで動作するためLinuxカーネルのバージョンに依存せず利用することが可能。最大ノード数は16で、アクティブ/パッシブ(純粋なHA)、アクティブ/アクティブ(HA+HPC)のどちらでも利用可能。Linux-HAは、このほかにも以下のような特徴を持っているという。 このなかでも仮想化サポートは、サーバ仮想化がIT業界の注目トピックとなっている昨今では重要な機能といえるだろう。仮想化によるサーバ集約はハードウェアトラブルに伴うリスクを増大させる(1台の物理サーバのダウンが多数の仮想サーバのダウンにつながるため)が、物理サーバをHAクラスタ化することでそのリスクを低減することができるという。Linux-HAの仮想化サポートは、仮想化ソフトウェアの種類にかかわらず利用できるそうである。 最後にRobertson氏は、Linux-HAで今後の改良が必要となる項目として以下のようなものを挙げたうえで、「将来的にどのような機能が必要となるのか皆さんで考えて教えてほしい」と聴講者に語りかけ、講演を締めくくった。 午後2つ目の講演は、Red HatのDavid S. Miller氏による「Horizontal Scaling and its Implications for the Linux Networking」。Miller氏はLinuxカーネルのネットワークサブシステムのメンテナーを務める人物だ。この講演で氏は、コンピューティングのトレンドが水平方向の拡張性に向かっている現状を解説し、それがLinuxにどのような影響を与えているのかを説明した。 最初にMiller氏が題材として取り上げたのは、プロセッサの進化の歴史である。氏は、現在のプロセッサが備える各種機能が主にメモリレイテンシを隠蔽するために追加されてきたものであると説明し、パイプラインやキャッシュ、スーパースカラーおよびそれらの多段化・大規模化は垂直方向にスケールするための拡張であり、水平方向への拡張が始まったのはIntelのPentium 4のハイパースレッディング以降であると指摘。そしてこの傾向を最大限に具現化したものがSunのNiagaraシリーズであるという。Niagaraは非スーパースカラーのコアを8つ備えており、コア当たり4同時スレッド(Niagara 2は8同時スレッド)をサポートする。実行スレッドの切り替え機構は極めて単純であり、各スレッドをランドロビンでスイッチするだけ。分岐予測も行わない。多数のシンプルなコアでプロセッサの作業負荷を高めることで、メモリレイテンシの影響を下げるという新しい考え方で設計された、エポックメイキングなプロセッサと言える。 次にネットワークに話題を移したMiller氏は、ネットワークのEnd-to-Endの原則を紹介した。 そしてこの原則をうまく適用した例としてMiller氏が挙げたのがDNSである。DNSは分散した多数のサーバが協調動作することで機能しており、ドメインレベルごとの権威を分散することでスケールするようにできている。一方、悪い例として挙げられたのがHTTP(Web)だ。Webサーバは一極集中型のネットワークモデルに基づいており、たとえるならばルートネームサーバしかないDNSのようなものであるという。しかも、動的コンテンツが主流になっている昨今では、Webキャッシュやレプリケーションサーバは部分的な解決策にしかならないため、効率よくスケールさせることができない。 この2つの例を下敷きとしてMiller氏は、「ネットワークサービスをスケールさせるためにはローカルキャッシュをうまく利用する必要があり、そのためにはプロトコルを注意深く設計しなければならない」と訴える。具体的にはクライアントは「サーバXに情報Yを要求する」のではなく単純に「情報Yを要求する」ように設計し、Yを特定する方法とデータの整合性を確保する方法を実装する。その現代的な例がBitTorrentであるという。 さらに、このEnd-to-Endの原則を手元のコンピュータにまで拡張すると、システム内の各プロセッサをそれぞれ独立したエンドノードとしてみなすことができるという。そして、エンドノードにネットワークを介して(単純な情報ではなく)何らかの処理が送られてくるようになる。このような状況になってくると、ネットワークから送られてきた処理をシステム内で負荷分散する仕組みがネットワークデバイス(ネットワークカード)に必要になるが、そうした仕組みは別の問題――例えばパケットのリオーダリングによるパケットロス――を引き起こすことにもなりかねない。そこで、パケットを処理ごとにグループ化して管理するために、PCI MSI-X割り込みに対応したマルチキューのネットワークデバイスが開発されている。Miller氏がそうした製品の例として紹介したSunのNEPTUNE 10 Gigabit Etnernet chipsetは、TXパケット用とRXパケット用のキューをそれぞれ複数持つことができ、キューを仮想マシンのゲストノード(XenのdomU)に割り当てることもできるそうである。 さて、こうしたネットワークデバイスの登場に対応するために、Linuxのネットワークサブシステムにも変更が加えられている。変更されたのはRXパケットを処理するためのポーリング機構であるNAPI(New API)であり、従来はネットワークデバイスごとに1つのコンテキストしか保持できないかったものが、複数のコンテキストを扱えるように改良されたとのことである。ただし、TXパケットにおけるマルチキュー対応は不完全な状態であり、TXパスのロックのマルチスレッド化、マルチキューに適したTXパケットスケジューラの構成変更、ドライバから共通して利用できるTXロードバランスレイヤとその構成をユーザースペースから設定するためのインタフェースの追加といった作業が必要であるとのことだ。 The Linux Foundation Japan Symposiumでは、毎回日本人開発者による講演が少なくとも1つ行われるのが恒例となっているが、今回は日立の大島 訓氏による「Linuxにおけるリソース管理の改善」と題された講演が行われた。この講演で大島は、日立の開発者によって作成されLinuxカーネルに取り込まれたパッチを2つ紹介した。 1つ目は河合英宏氏によるcoredump maskingで、これはアプリケーションがクラッシュした際にどのタイプのメモリ領域のコアを取得するのかをプロセスごとに指定できるようにするものだ。もともとの発想は、巨大な共有メモリを利用するマルチプロセスのアプリケーションがクラッシュした際に、プロセスごとに共有メモリをダンプするのはディスクスペースおよび時間の無駄であるという考えである。完成したcoredump maskingでは、「anonymousかつprivate」、「anonymousかつshared」、「file-backedかつprivate」、「file-backedかつshared」という4タイプの領域ごとにコアダンプを取るかどうかを設定することができる。 2つ目はUDPでもカーネルが使用するメモリの上限値を設定可能にするパッチで、こちらは大島氏と青木英郎氏、安井隆弘氏によるもの。従来のLinuxカーネルにはUDPソケットバッファのサイズに上限がないという問題があり、これを悪用するとシステムがダウンするまでカーネルページを無制限にピンダウンするといった攻撃がユーザースペースから実行できてしまうそうである。そこでこの問題に対処するためにパッチの開発に取りかかったものの、当初はTCPのメモリアカウンティングと同様の機能をUDPに実装する方針だったものが、最終的にはTCPのメモリアカウンティングを削除して新たにstream/datagram汎用のメモリアカウンティングを実現するものになったそうだ。 大島氏の講演では、それぞれのパッチをLKML(Linux Kernel Mailing List)で提案した際にどのようなフィードバックを受けて、どのように設計・実装を変更したのかといった開発経緯の説明に重きが置かれていた。大島氏がLKMLでのやり取りから得た教訓には、以下のようなものがあるそうだ。 以上、本稿では第7回 The Linux Foundation Japan Symposiumの講演内容を紹介した。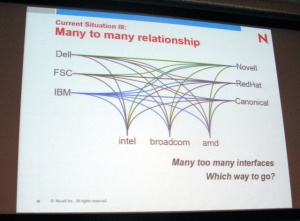
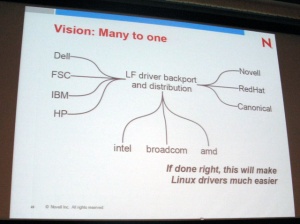
ワーキンググループがハブとして機能することで、ドライババックポートのインタフェースを簡素化する
メモリ管理の現状と問題

HAクラスタの市場を拡大するLinux-HA


水平方向の拡張とネットワークにおける課題

カーネルコミュニティでうまく立ち回るには

![]()
![]()