さまざまなログをまとめて集中管理できるログ記録/管理ツール「fluentd」
大規模なサービスを運用する場合、それらのログ管理をどうするか、というのが1つの問題となる。複数のマシンにログが分散すると、その管理や活用が面倒になるからだ。また、クラウド環境ではサーバーのリブートによってローカルのストレージが失われる場合がある。このような場合、別のマシンにログを転送するような仕組みが求められる。今回はこういった場合に有用なログ記録・管理ツール「fluentdを紹介する。
さまざまな方法でログを収集できるfluentd
今回紹介するfluentdは、Treasure Dataが開発するログ収集管理ツールだ(図1)。オープンソースで公開されており、Linuxや各種UNIXで動作する。
ログ収集のためのソフトウェアとしてはsyslogdやsyslog-ngなどが有名だが、fluentdがこれらと異なる点としては、以下が挙げられる。
さまざまなソースからのイベントをさまざまな媒体に出力できる
fluentdの大きな特徴としては、ログの収集方法やログの記録先などを柔軟にカスタマイズできる点がある。
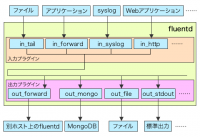
一般的にログ収集ソフトウェアは何らかの「イベント」を検知し、その内容を発生時刻などの情報とともにファイルやデータベースなどのストレージなどに出力する、という処理を行うが、fluentdではイベントの受け取り(input)およびストレージなどへの出力(output)がすべてプラグインとして実装されている(図2)。
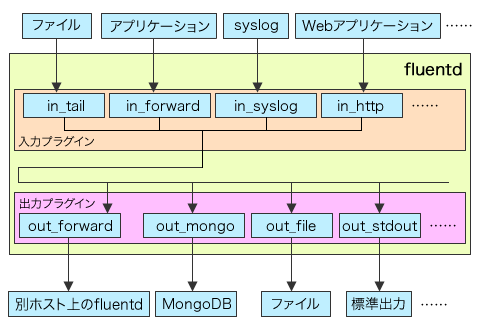
inputプラグインについてはsyslog互換プロトコルやMessagePackベースの独自プロトコル、HTTPのPOSTリクエスト、Unix Domain Socketなどを使うものや、任意のテキストファイルを監視してそこにテキストが書き込まれたらそれをイベントとして受け取る、といったものなどが用意されている。outputプラグインについては標準出力への出力やテキストファイルへの書き出し、MongoDBへの書き込み、任意のコマンドを実行してそこにログデータを渡す、といったものが用意されている。
また、サードパーティによって開発されたプラグインも多く公開されており、さらに自分でプラグインを作成することも可能だ。fluentdやそのプラグインはRubyで実装されており、Rubyの知識があれば比較的容易にfluentdの機能を拡張できる。
ログの種類はタグで管理される
fluentdでは、ログの管理を「タグ」と呼ばれる情報で管理する。タグはイベントを発生させる側やinputプラグイン側で任意の文字列を指定できるが、以下のように「.」を使った階層構造を取るのが一般的だ。
<親タグ名>.<子タグ名>
「foo.bar.hoge」のように3階層以上の構造を持つタグを指定することもできる。
ログの内容はJSON形式
fluentdではログの内容(レコード)がJSON形式になっている。そのため、アプリケーション側でのパースが容易であるというメリットがある。最近ではMongoDBなどのJSON形式をネイティブで扱えるデータベースも登場しており、これらと組み合わせることでデータの解析などがやりやすくなる。
さまざまな言語向けのモジュールが提供されている
fluentdでは、イベントを送信するためのモジュールがさまざまな言語で用意されている。公式のものとしてはRubyやJava、Python、PHP、Perl、Node.js、Scala向けのモジュールが提供されているほか、サードパーティによってこれ以外の言語向けのモジュールも開発されている。これらを利用することで、独自のアプリケーションのログをfluentd経由で簡単に記録させることができる。
fluentdが適している分野
fluentdはさまざまな環境で利用できるが、やはり多く使われているのはWeb関係の分野だろう。たとえば、一定以上の規模のWebサービスではロードバランサを使ってリクエストを複数台のWebサーバーに分散させる構成が一般的だ。このような構成の場合、fluentdを使ってWebサーバーのアクセスログを処理することで、ログを1つのデータベースに集約することが可能になる。
また、アクセスログに加えてWebアプリケーションから直接fluentdにログを記録させることで、より粒度の高いロギングが可能になる。
クラウド環境においてもfluentdは有用だ。クラウドサービスで提供される仮想マシンでは、ストレージの永続化がサポートされていない(サーバーを停止/再起動させた際にストレージがクリアされる)ことも多い。そのため、各種ログは仮想マシン外の永続的ストレージに記録する必要がある。fluentdを利用すれば、外部ストレージへのログ記録と複数サーバーのログ集約が容易に行える。
fluentdの設定手順
続いては実際にfluentdを利用するために必要な設定手順などを紹介しておこう。以下では、Red Hat Enterprise Linux 6.3互換であるCent OS 6.3上に、fluentdの開発しているTreasure Dataが提供しているRPMパッケージを使ってfluentdをインストールする例を解説する。
fluentdのインストール
fluentdのソースコードはGitHubで公開されている。ただ、通常はソースコードからではなく、RPMやDeb形式のパッケージ、もしくはRuby Gemを利用してインストールするほうが一般的だ。なお、Ruby Gemで(もしくはソースコードから)インストールを行う場合はRuby 1.9.2が必要となるが、fluentdの開発元であるTreasure Dataが提供しているRPM/DebパッケージにはRuby 1.9系があらかじめ含まれているので、こちらを利用する場合は別途Rubyをインストールする必要はない。Red Hat Enterprise Linux(RHEL) 6やその互換ディストリビューションなど、まだRuby 1.9系を公式にサポートしていない環境ではRPM/Debパッケージを利用することをおすすめする。
それ以外の環境でのインストール方法については、ドキュメントが用意されているので、そちらを参照してほしい。
RPMパッケージを使ったインストール
fluentdの開発元であるTreasure Dataでは、RHEL5/6およびその互換環境向けのRPMリポジトリや、簡単にfluentdをインストールできるシェルスクリプト(http://toolbelt.treasuredata.com/sh/install-redhat-td-agent2.sh)を公開している。このシェルスクリプトをダウンロードして実行すれば、それだけでfluentdのインストール作業が完了する。
手動でTreasure Dataが提供するyumリポジトリを利用する設定を追加することもできる。Treasure Dataのyumリポジトリを利用するには、まずTreasure Dataが提供する署名検証要のGPG鍵をインポートする。
# rpm --import http://packages.treasuredata.com/GPG-KEY-td-agent
続いて、以下の内容が含まれた設定ファイルを「/etc/yum.repos.d/td.repo」として作成する。
[treasuredata] name=TreasureData baseurl=http://packages.treasuredata.com/2/redhat/\$releasever/\$basearch gpgcheck=1 gpgkey=http://packages.treasuredata.com/GPG-KEY-td-agent
Treasure Dataが提供するリポジトリではfluentdが「td-agent」というパッケージで提供されている。以上の作業で、yumコマンドでこのパッケージがインストールできるようになる。
# yum install td-agent
このとき、fluentdの設定ファイルは/etc/td-agent以下に、ログは/var/log/td-agent/以下に保存される。また、fluentdの起動や停止は、/etc/init.dディレクトリ以下に格納されるtd-agentスクリプトで行える。起動するには以下のように「start」引数付きでこのスクリプトを実行すれば良い。
# /etc/init.d/td-agent start
また、fluentdを停止させるには以下のようにする。
# /etc/init.d/td-agent stop
もちろん、RHEL互換ディストリビューションで使われているserviceコマンドやchkconfigコマンドでの制御も可能だ。
# service td-agent
Usage: td-agent {start|stop|reload|restart|condrestart|status|configtest}
# service td-agent status
td-agent は停止しています
# chkconfig td-agent --list
td-agent 0:off 1:off 2:off 3:off 4:off 5:off 6:off
なお、fluentdのドキュメントではインストール前の作業として、NTPを使ったサーバーの時刻設定や、ファイルディスクリプタの上限数の設定、カーネルパラメータの最適化などが提示されている。これらは必須ではないが、問題の原因となる可能性もあるので、確認したうえで必要に応じて適用しておくと良いだろう。