Webページのローカル保存に便利な「ScrapBook」拡張
Webページを巡回していると、そのページを保存したい、収集したいと思うことがある。その際には、Firefoxのページ保存機能を使ったり、以前紹介した「Pearl Cresent Page Saver Basic」を使ってキャプチャするなどという方法がある。しかし、Webページ全体を取り込んでおきたいという欲求に答えるには、これらでは少々物足らない。リンク先も含めたWebページを保存するには、別なツールが必要となる。そこでオススメしたいのが、「 ScrapBook 」というアドオンだ。
これを使うことでWebページの収集が格段に楽になる。ScrapBookでは、Webページの保存のほか、選択範囲の保存、下位層も含めたWebサイトの保存、コレクションの管理、マーカーなどのWebページ編集機能、全文検索や高速フィルタリング機能、テキスト編集機能などを備えている。
インストールするには、FirefoxアドオンサイトのScrapBookのページで、「Firefoxへインストール」をクリックする。すると確認ダイアログが表示されるので、「今すぐインストール」ボタンをクリックして、指示に従ってFirefoxを再起動すればいい。これでインストールは完了だ。
再起動時には、ほかのアドオンのインストール時と同様に、「アドオン」ダイアログが開き、「拡張機能」タブにScrapBookが追加されていることが確認できるが、まずはここで「設定」をクリックして、いくつかの初期設定をしておきたい。なお、この設定ダイアログはScrapBookのサイドバーの「ツール」→「設定」でも表示できる(サイドバーを表示するにはメインメニューの「ScrapBook」→「サイドバーに表示」をチェック)。このサイドバーでは、ブックマークのように収集したWebページを管理することができる。このことに関しては後述したい。
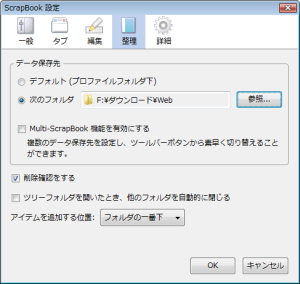
さて話を戻すと、「ScrapBook設定」ダイアログが開いたら、「整理」タブで取り込んだデータの保存先を設定しておこう(図1)。デフォルトでは「プロファイルフォルダ下」が設定されているが、データは分けて保存したいという人も多いだろう。そういう場合は、「次のフォルダ」にチェックを入れ、「参照」をクリックする。ここで既存のフォルダを指定、または新規作成すればいい。これで、指定されたフォルダにデータが保存されることとなる。データの保存先を設定したら、「OK」をクリックして設定ダイアログを閉じよう。
準備が完了したら、Webページの取り込みをやってみよう。Webページを単体で取り込むのならば、保存したいページ上で右クリックし、メニューから「ページの取り込み」→「ルートフォルダ」を選択する。これで「データ保存先」として指定したフォルダ以下にデータが格納される。「ページの取り込み」→「フォルダ選択」を選べば、別のフォルダを指定することも可能だ。
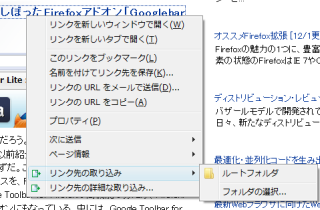
また、ページで部分選択し、その部分のみを保存することもできる。その場合は、範囲を選択してから右クリックし、「範囲選択の取り込み」から同じように保存すればいい。同様に、リンク先を保存したい場合は、リンク上で右クリックし、「リンク先の取り込み」から保存先を選択する(図2)。
保存したページを閲覧するには、ScrapBookサイドバーを表示させて目的のページをクリックするか、メニューの「ScrapBook」の下に追加されたページタイトルを選択すればいい。アドレスバーの表示がローカルファイルになってページがきちんと表示されたはずだ。ScrapBookは、Firefoxの「名前を付けてページを保存」ではきちんと保存できないページでも、ほぼそのまま保存することができる。
ここまではWebページを単体で保存しているに過ぎない。別に、ローカルに保存されたファイルのリンクがローカル同士に再設定されているわけではないのだ。Webサイトをまとめてダウンロードするのには、通常の取り込みではなく、「詳細な取り込み」を選択する必要がある。
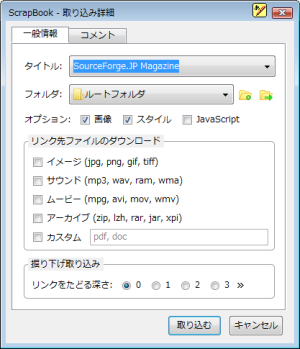
保存したいWebページ上で右クリックし、「ページの詳細な取り込み」を選択する。すると、「取り込み詳細」というダイアログが表示されるはずだ(図3)。ここでは、保存フォルダや、画像、スタイル、JavaScriptといったオプション、そしてリンク先ファイルのダウンロード、リンクをたどる深さなどを設定できる。画像やスタイルは保存しても問題ないだろうが、JavaScriptは問題を引き起こす可能性もあるためか、非推奨となっており、デフォルトではチェックが外されている。
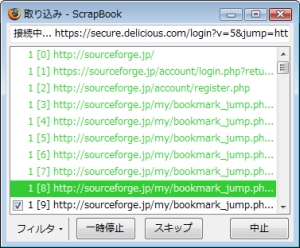
またデフォルトでは「掘り下げ取り込み」の深さが「0」になっている。こればWebページ単体での取り込みを意味する。これを試しに3にして、リンク先の画像なども取り込み対象として実行してみると、「取り込み」ダイアログが表示されて、徐々に取り込まれる様子をうかがうことができる(図4)。もちろん、予想以上に取り込み対象が多くなってしまった場合などのために、一時停止、スキップ、中止なども可能である。フィルタも用意されており、ドメインやディレクトリ、文字列などで制限をかけることもできる。
この機能は実に強力で、深い階層のリンクまでたどって保存可能なため、Webサイト全体の保存ができる。取り込みが完了すると、取り込まれたすべてのページが相互にリンクされ、ローカルでの閲覧が可能となる。さらに、サイトマップページも自動生成されるのは便利だ。なお、JavaScriptによるポップアップウィンドウのリンクがあった場合は、可能な限り通常のリンクへと変換される。
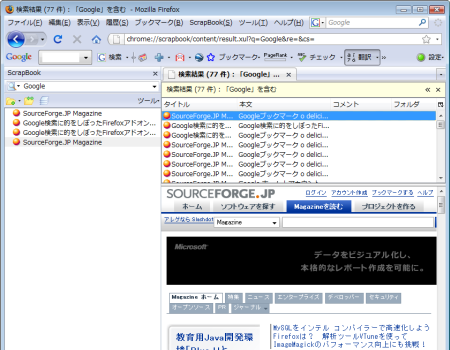
ローカルにWebページをどんどん保存したら、どこに何があったか忘れてしまわないかと心配する人もいるだろう。ScrapBookには強力な検索機能も備わっているので心配いらない。検索ボックスに適当なキーワードを入力してみよう。すると、右画面の上部に検索結果がリスト表示される。その中の一つを選択すると、下画面にページが表示されるのだ(図5)。
ScrapBookには機能が満載で、まだまだ説明したりないが、実際に使いながら学んでみて欲しい。少しばかり紹介すると、取り込んだページから不要部分をカットしたり、重要な部分にマーカーをつけたり、注釈を付けてみたりといった強力な編集機能も用意されている。この編集機能は、取り込み前に実行することもできる。また、URLのリストを指定してWebページを次々に取り込める「URL一括取り込み」なども用意されている。Webページをローカルに保存したい人にとっては必須のアドオンと言えるだろう。