Python+tweepy+web.py+Azureストレージで作るTwitter連携アプリケーション 5ページ
Tableストレージの利用例:Twitterからの情報を収集するアプリケーション
Tableストレージは表形式でデータを格納するため、シーケンシャルなデータの保存に向いている。今回はTableストレージの利用例として、Twitterから情報を収集して格納し、整形して出力するサンプルアプリケーションを紹介する。
サンプルアプリケーション「Image Aggregator」は、あらかじめ指定しておいた複数のTwitterアカウントに定期的にアクセスし、画像を含むTweetだけを保存・マージして時系列に並べて表示するものだ。(図10)。画像データ本体の保存は行わず、外部の画像投稿サービス内にある画像をインラインで表示する形としている。

Image AggregatorはPythonで実装されており、Webアプリケーションフレームワーク「web.py」やTweeterにアクセスするライブラリ「tweepy」、テンプレートエンジン「Mako」といったモジュールを利用している。また、Python向けのWindows Azureストレージラッパーには「winazurestorage」を利用している。ただしwinazurestorageはTable関連機能の多くが実装されておらず、またいくつか不具合も確認されている。そこで今回はオリジナルのwinazurestorageに対し修正を加え、さらに不足している機能を追加実装した「wazs.py」というモジュールを使用している。修正/機能追加済みのwinazurestorageやwazs.pyはPersonalForgeにて公開している。
また、ImageAggregatorの全ソースコードも同じくPersonalForgeやWindows Azure記事サンプルコードページで公開している。下記では主要な部分のみを抜粋して解説するので、ソースコード全文についてはこちらをご参照していただきたい。
テーブルを設計する
アプリケーションのソースコードを紹介する前に、アプリケーションで使用するテーブルの構造について説明しておこう。Image Aggregatorアプリケーションでは、下記2つのデータが必要となる。
- Tweetの取得対象とするユーザーの情報
- 取得したTweet
今回は前者を「followers」というテーブルに、後者を「tweets」というテーブルに格納することにする。まずfollowersテーブルであるが、ここに格納する情報は次のとおりだ。
- ユーザーID(screen name)
- 取得を行うか否か
- 最後に取得したTweetのID
Tableストレージでは、前述のとおり「パーティションキー」と「行キー」の2つのキーが最低でも必要である。そのため、まずこの2つのキーにどの情報を格納するかを決定しなければならない。今回、格納する情報の中でエンティティごとに重複せず、かつ不変な情報はユーザーIDのみである。そこで、パーティションキーは「follower」という文字列で固定し、行キーにユーザーIDを格納することにした。これを踏まえたデータベースの構造は表8のようになる。なお、「Timestamp」プロパティは自動的に作成されるプロパティだ。
| キー名 | 型 | 内容 |
|---|---|---|
| PartitionKey | string | 「follower」という文字列 |
| RowKey | string | TwitterID |
| Timestamp | timestamp | エンティティのタイムスタンプ |
| Enabled | bool | 取得を行うか否か |
| LastTID | int64 | 最後に取得したTweetのID |
実際にデータを格納したテーブルを第1回で紹介したWindows Azureストレージ操作ツール「Azure Storage Explorer」で可視化すると、図11のようになる。
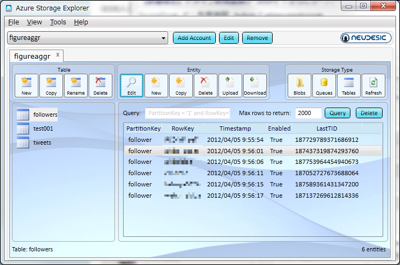
また、取得したTweetを格納する「tweets」テーブルには、次のような情報を保存する。
- Tweetの固有ID
- 投稿時刻
- 画像のURL
- 使われている画像投稿サービスにおける画像URL
- Tweet本文
- TweetしたユーザーのID
こちらについても不変かつ一意な情報はTweetの固有IDのみだ。そのためfollowersテーブルと同様、パーティションキーには「tweet」という文字列を指定し、Tweetの固有IDを行キーに設定している(表9)。
| キー名 | 型 | 内容 |
|---|---|---|
| PartitionKey | string | 「tweet」という文字列 |
| RowKey | string | Tweetの固有ID |
| Timestamp | timestamp | エンティティの作成日時 |
| CreatedAt | timestamp | Tweetの投稿日時 |
| ImageURL | string | 画像生データのURL |
| OriginalImageUrl | string | 画像投稿サイトにおける対応する画像URL |
| Text | string | Tweet本文 |
| UserID | string | TweetしたユーザーのID |
実際にデータを格納したテーブルをAzure Storage Explorerで可視化すると、図12のようになる。
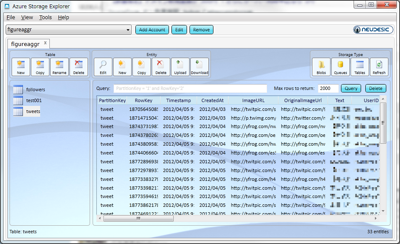
テーブルの作成
Tableストレージを利用する際は、あらかじめ使用するテーブルを作成しておく必要がある。今回は「createtable.py」というスクリプトを用意し、このスクリプトを手動で実行してテーブルを作成している(リスト7)。
リスト7 テーブルを作成するスクリプト(createtable.py)
#!/usr/bin/python
# -*- coding: utf-8 -*-
from winazurestorage import CLOUD_TABLE_HOST
import wazs
from config import config
def main():
st = wazs.TableStorage(CLOUD_TABLE_HOST,
config["storage_account"],
config["storage_key"])
st.create_table(config["follower_db"]);
st.create_table(config["tweet_db"]);
if __name__ == "__main__":
main()
winazurestorage.py中にはテーブル操作用のTableStorageクラスが用意されているので、まずはこのオブジェクトを作成し、続いてcreate_table関数でテーブルを作成している。create_table関数は引数で指定したテーブルを作成する関数だ。
TableStorageのコンストラクタにはアクセス先ホスト名(table.core.windows.net)およびストレージアカウント、アクセスキーを指定する。今回は「config.py」というファイル中にこれらの情報を記述しておき、「config[“<キー名>”]」という変数でアクセスできるようにしている。
テーブルへのアクセス
データベースアクセスを行うプログラムを作成する場合、データベース関連処理をまとめたクラスを作成するのが一般的だ。今回はfolloersテーブルに関連する処理を行うクラス「FollowerDB」と、tweetsテーブルに関連する処理を行うクラス「TweetDB」を作成し、そこにTableストレージへのアクセス処理をまとめている。
MySQLなどのストレージを利用する場合、このようなクラスはSQLの発行やデータの中継のみを行うことが多いだろう。しかしTableストレージの場合、インターネット経由でのクエリを行うこともあり、クエリを発行してから結果が帰ってくるまでにやや時間がかかることもある。そのため、迅速な処理が求められる場合は何らかのキャッシュ機構を用意する必要がある。今回はオブジェクト内にデータをキャッシュしておき、必要に応じてデータベースと同期することで高速化を行っている。
たとえばFollowerDBでは、list形式でユーザーID(uid)をキャッシュするようになっている。エンティティが更新されたかどうかはユーザーIDをキーとする「_is_dirty」ディクショナリにBool値で保存しておき、更新された(_is_dirtyがTrueとなる)のエンティティに対してのみTableストレージの更新を行う、という処理を行っている(リスト8)。
リスト8 キャッシュとTableストレージの同期処理(followerdb.py)
def update_db(self):
ent = TableEntity("", "", {})
for uid in self:
if self._is_dirty[uid]:
ent.partition_key = "follower"
ent.row_key = uid
ent.add_property("LastTID", long(self.last_id_of[uid]))
ent.add_property("Enabled", self.is_enabled[uid])
self._update_table(ent)
self._is_dirty[uid] = False
ここで使われているTableEntityクラスはエンティティを表すクラスだ。partition_key要素がパーティションキー、row_key要素が行キーを示す要素で、それ以外のプロパティは「add_property」関数で追加する。
テーブルの更新は_update_table関数内で行っている。ここではTableStorageクラスのオブジェクトを作成するself._get_ts関数を呼び出し、続いて渡されたエンティティのパーティションキーおよび行キーに該当するテーブルエンティティの更新をupdate_entity関数で行っている(リスト9)。
リスト9 テーブルの更新処理(followerdb.py)
def _update_table(self, entity):
ts = self._get_ts()
err = ts.update_entity(config["follower_db"],
entity.partition_key,
entity.row_key,
entity)
if err == 400:
print "error in followerdb:", entity.__repr__()
なお、update_entity関数の引数は次のようになっている。
update_entity(<テーブル名>,<パーティションキー>,<行キー>,<更新後のエンティティ>
Twitterへのアクセス
今回作成したアプリケーションでは、「gettimeline.py」スクリプトを定期的に実行することでTweetの収集を行っている。Windows Azure環境で定期的にスクリプトを実行させるには、タスクスケジューラを利用すれば良い。タスクスケジューラは設定ツールが用意されているが、コマンドラインでも「schtasks」コマンドでタスクを登録できる。たとえば30分おきにgettimeline.pyスクリプトを実行させるには、次のコマンドを実行すれば良い。
> schtasks /RU SYSTEM /SC MINUTE /MO 30 /TN "Receive Update Request" /TR '"<Pythonのパス>" "<gettimeline.pyのパス>'
このgettimeline.py内で行っている処理は次のとおりだ。
- followersテーブルからタイムラインを取得するユーザー一覧を取り出す(main関数)
- ユーザーの公開タイムラインを取得し、Tweetに画像が付いているかをチェックする(get_timeline関数)
- 画像が付いているTweetからそのURLなどを抜き出し、tweetsテーブルに保存する(get_image_url関数およびget_timeline関数)
まず、followersテーブルからユーザー一覧を取得する部分のコードがリスト10だ。
リスト10 followersテーブルからユーザー一覧を取得するコード(gettimeline.py)
def main():
# ①Tableストレージアクセスクラスの作成
f_db = FollowerDB()
f_db.load_from_db()
t_db = TweetDB()
t_db.load_from_db()
# ②followersテーブルから取得したユーザー一覧に対し
# ユーザーごとにget_timeline関数を実行する
for uid in f_db:
last_id = f_db.get_last_id(uid)
read_id = get_timeline(t_db, uid, last_id)
t_db.create_cache()
f_db.update(uid, read_id)
①の部分でストレージアクセスクラスの作成とストレージからのデータ読み出しを行い、②の部分でユーザーごとにget_timeline関数を実行している。
各ユーザーのタイムライン取得は、tweepy.apiに含まれるuser_timeline関数で行っている(リスト11)。
リスト11 ユーザーのタイムライン取得コード(gettimeline.py)
def get_timeline(tweetdb, uid, last_id):
api = tweepy.api
st = api.user_timeline(uid, include_entities=True)
read_id = last_id
print "get timeline for " + uid
今回は公開されているタイムラインのみを対象としているので認証は不要だ。user_timeline関数の第1引数では取得対象のユーザーIDを指定する。include_entities引数にはTrueを指定し、同時にエンティティの取得も行っている。エンティティはTweet内に含まれる画像やURLといた情報を含むデータで、これを利用することでTweet本文を解析することなしに画像データやURLなどの情報を取得できる。
user_timeline関数は取得したTweet情報を含む「Status」オブジェクトのリストを返すので、続けてこのリストの各要素を対象に画像を含んでいるか判断する処理を実行する(リスト12)。
リスト12 取得したTweetが画像を含んでいるかを調査するコード(gettimeline.py)
for s in st:
# すでに取得済みのIDはスキップする
if s.id <= last_id:
continue
# 「read_id」はすでに取得したTweetの中で
# もっとも大きいID(「このIDまで読んだ」情報)
if read_id < s.id:
read_id = s.id
# Tweet内にURLが含まれている場合、その情報は
# entities要素内に「urls」というキーで
# その情報が格納される
if s.entities.has_key("urls"):
for url in s.entities["urls"]:
# URLが対応する画像サービスのものかを判定
media_url = get_image_url(url["display_url"])
# 対応する画像サービスであれば画像の
# 直リンクURLがmedia_url変数に格納されている
if len(media_url) > 0:
# Tweetクラスのオブジェクトを作成して
# tweetsテーブルに格納する
tw = Tweet(media_url, uid, s.id, s.created_at, s.text, "http://" + url["display_url"])
tweetdb.append(tw)
debug_print("add tweet: '%s'(%d) by %s" %
(s.text, s.id, uid))
# Twitter公式の画像ストレージを使っている場合
# entities要素内に「media」というキーで
# その情報が格納される
if s.entities.has_key("media"):
for media in s.entities["media"]:
url = media.get("media_url", "")
if len(url) > 0:
tw = Tweet(url, uid, s.id, s.created_at, s.text, media.get("expanded_url", ""))
tweetdb.append(tw)
debug_print("add tweet: '%s'(%d) by %s" %
(s.text, s.id, uid))
return read_id
なお、Twitter公式の画像アップローダにアップロードされた画像についてはエンティティ内に直接その画像を取得できるURLが含まれているが、それ以外の画像アップローダを利用したTweetの場合は自前で画像URLを取得する必要がある。今回はtwitpicおよびyfrogについて、そのURLから画像URLを取得するコードを用意している(リスト13)。
リスト13 Tweetに含まれるURLが対応する画像共有サービスのものかを判断するコード(gettimeline.py)
def get_image_url(url):
if url.find("twitpic.com/") == 0:
fig_id = url.replace("twitpic.com/", "")
return "http://twitpic.com/show/large/" + fig_id
elif url.find("yfrog.com/") == 0:
fig_id = url.replace("yfrog.com/", "")
return "http://yfrog.com/" + fig_id + ":iphone"
else:
return ""
テーブルに格納したデータからHTMLを出力する
HTMLの表示を行うCGIスクリプトが「index.py」ファイルだ。index.pyではweb.pyを利用してページングなどのパラメータ処理を行い、テンプレートを元に適切なHTMLを作成してページを表示している。
今回はtweetsテーブルからデータを取得し、そのデータを丸ごとテンプレートエンジンにそのまま渡し、データの処理はテンプレート側で行っている(リスト14)。
リスト14 tweetsテーブルから取得したデータは丸ごとテンプレートに渡している(index.py)
class Index(BaseController):
def GET(self):
i = web.input(page=1,view="thumbnail")
page = int(i.page)
if page < 1:
page = 1
tdb = TweetDB.from_cache()
tdb.sort_localcache()
if i.view == "timeline":
tweets = tdb.get_subtweets((page-1)*10, 10)
html = self.render("index.html", tweets=tweets, page=page)
else:
tweets = tdb.get_subtweets((page-1)*30, 30)
html = self.render("thumbnails.html", tweets=tweets, page=page)
web.header('Content-Type', 'text/html')
return html
まテンプレート内でTweetに相当する情報を書き出している部分はリスト15のようになっている。
リスト15 テンプレート内のTweet書き出し部分(template/root.html)
<div role="main" class="main">
% for tw in tweets:
<div class="tweet">
<div class="twitterid"><a href="http://twotter.com/">@${tw.user_id}</a>:</div>
<div class="text">${tw.text}</div>
<div class="image">
<a href="${tw.original_url}"><img src="${tw.image_url}" width="400"></a>
</div>
<div class="date">
<span><a href="http://twitter.com/#!/${tw.user_id}/status/${tw.tweet_id}">${tw.get_localtime()}</a></span>
</div>
</div>
% endfor
</div><!-- .main -->
ここでは割愛したが、ソースコード中には対象ユーザーの追加/削除といった管理機能のコードや、キャッシュのローカルストレージへの保存といったコードも含まれている。アプリケーション全体については公開しているソースコードを確認していただきたい。