XapianとOmegaでWebサイトに検索機能を追加する
Xapian と Omega を使えば、Webサイト向けの強力な検索インタフェースを手軽に構築できる。HTML、PDF、PHPコンテンツのインデキシングを行い、そうしたドキュメントに含まれるメタデータまたは単語で検索をかけられるようになる。
インデキシングの実装には、Xapianという共有ライブラリが使われている。また、Xapianの開発チームが、ソフトウェア開発者でなくてもこのライブラリをインデキシングおよび検索に使えるように構築した一連のツール群がOmegaである。OmegaはXapianを利用しているため、使っているディストリビューションのパッケージリポジトリにOmegaが含まれていれば、Omegaのインストール時にXapianも一緒に依存関係モジュールとしてインストールされる。
Omegaのパッケージは、openSUSEの1-Clickインストールに対応し、Ubuntu HardyのUniverseリポジトリからインストールできる。ただし、Fedora 9の場合はXapianだけがxapian-core-develとしてパッケージ化されている。今回はこのXapianパッケージをインストールしたうえで、Omegaバージョン1.0.8のソースからのビルドを64ビット版Fedora 9マシンで行った。その際のコマンドは、例によって「./configure; make; sudo make install」である。Omega本体のほか、ドキュメント、設定ファイル、マニュアルページも同時にインストールされる。また、次のコマンドでWeb検索インタフェースのセットアップも行う必要がある。
# mkdir -p /var/lib/omega/data/default
# cp -av xapian-omega-1.0.8/templates /var/lib/omega
# chown -R root.apache /var/lib/omega
# find /var/lib/omega -exec chmod +s {} \;
# cp -av /usr/local/lib/xapian-omega/bin/omega /var/www/cgi-bin
まず、Omegaのサイトテンプレートを、デフォルトの置き場所である「/var/lib」内のディレクトリにコピーする。このディレクトリのパーミッションはapacheユーザがアクセスできるように設定され、またスティッキービットを立てることでOmegaの作成する新規ファイルもapacheグループの管理下に置く。最後のコマンドでは、OmegaをWebブラウザから実行できるように、omegaバイナリをcgi-binディレクトリにコピーしている。
使い方
Omegaでは、omindexコマンドを使ってコンテンツのインデックスの作成、配置、更新を行う。また、多数のインデックスのそれぞれを個別のディレクトリに保存できる。ここでは、以下のコマンドに示すようにデフォルトのインデックス格納場所を用いる。指定が必要なのは、Omegaがインデックスを格納するパス、インデキシングの対象とするWebサイトのURLまたは相対パス、同じく対象のファイルが含まれるファイルシステムのパスである。以下のomindexを実行すると、すべてのファイルを対象としたインデックスがWebのDocumentRoot下に作成される。ここではWebサーバー全体のインデキシングを行うので、「--url」パラメータを単純に「/」としている。
# grep DocumentRoot /etc/httpd/conf/httpd.conf ... DocumentRoot "/var/www/html" ... # omindex --db /var/lib/omega/data/default --url / /var/www/html
多数のWebサイトがDocumentRoot下にある場合や、一部のサイトに限定した検索結果が得られるようにする場合は、最後の引数である「--url」で対象のパスを指定することで、特定のWebサイトについてのみインデキシングを実行できる。この「--url」オプションは、絶対URL指定のほか、より便利なURLの相対パス部分だけの指定にも対応している。
たとえば、1つのDocumentRootにLinuxのHOWTOサイトとビジネスWebサイトが含まれているとする。以下のコマンドでは、これらを対象としたインデキシングを個別に行っているため、それぞれが独立した2つのサイトとして記憶される。これにより、以降は一方のサイトだけを検索できるようになる。
# omindex --db /var/lib/omega/data/default \
--preserve-nonduplicates \
--url /howto \
/var/www/html/howto
# omindex --db /var/lib/omega/data/default \
--preserve-nonduplicates \
--url /mysite \
/var/www/html/mysite
通常はOmegaを実行すると、ファイルシステム内に見つからなかったドキュメントはインデックスから削除される。必ずWebサイト全体に対してomegaを実行している場合は、これが望ましい動作といえる。というのも、ファイルシステムから削除されたファイルは、インデックスからも削除する必要があるからだ。先ほどのように、omegaを何回かに分けて実行する場合は、たとえ現時点のインデキシングで見つからない要素があってもインデックスから消さずに残しておきたいと思うだろう。まさにそのためのオプションが「--preserve-nonduplicates」だ。このオプションを使えば、2番目のURLであるmysiteのインデキシングの際に、HOWTOファイルが見つからないからといってそのインデックスエントリが削除されることはなくなる。
上記のようにコマンドを分けるもう1つの利点は、双方のWebサイトのインデックスを個別に更新できることだ。一方のサイトが著しく大きい場合は、以下に示すような実行によってそのサイトの特定のサブディレクトリだけを更新することもできる。その場合は、サイトのURLとその参照パスは変えずに、インデックスを更新したいそのサイト内のサブディレクトリを追加するだけでよい。
# omindex --db /var/lib/omega/data/default \ --url /mysite \ --preserve-nonduplicates \ /var/www/html/mysite \ quickly/changing/dir
Omegaは、さまざまな種類のファイルのインデキシングに標準で対応している。HTML、プレーンテキスト、PHPはもちろん、PDF、PostScript、OpenOffice.org、Microsoft Office、AbiWord、RTF、DjVuのようなドキュメント形式、さらにはPerlのPODやTeXのDVIといった難解な形式のファイルもサポートされている。
こうしたドキュメントをOmegaでインデックス化しておけば、以下に示すようなomegaコマンドでそれらに対する検索が可能かどうかをチェックできる。ただし、適切なomegaバイナリを使用すること。私のシステムでは、texliveパッケージのomegaバイナリにパスが通っていて、Omegaに付属していたomegaバイナリよりもそちらが優先して使われるので、フルパスでコマンドを指定する必要があった。次のコマンドは、先ほど作成したインデックスに対して“load”という語の順位付きフルテキスト検索を実行する。
# /usr/local/lib/xapian-omega/bin/omega 'P=load' HITSPERPAGE=10
上の例のomegaバイナリはCGIインタフェースで使われるのと同じバイナリなので、「P=」というCGIパラメータプレフィックスを使ったフルテキストクエリを渡す必要がある。Omegaがインデックスを見つけ出してクエリを問題なく実行できることがわかったら、今度はWebインタフェースを使ってみよう。事前にコマンドラインで動作を確認しておけば、OmegaのWebインタフェースがすぐには動作しなかった場合でも、原因究明に関わる要因を1つ減らすことができる。Webインタフェースを利用するには、Webブラウザのアドレスバーに「http://localhost/cgi-bin/omega」というURLを入力する。これで、Omegaを使ったWebサイトの検索が行える。スクリーンショットは、HOWTOドキュメントの検索にOmegaを利用しているときの検索インタフェースである。
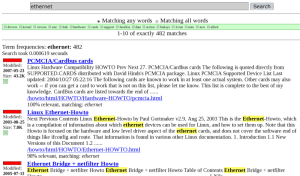
Omegaのクエリ構文では、ブール演算子のAND、OR、XOR、NOTが使える。また、「+」および「-」を使って、対象のドキュメントに含まれていなければならない、または含まれていてはならない用語を指定することもできる。「+」も「-」も使用しない場合は、クエリタームが順位付きで評価される(つまり、指定したクエリタームの一部が含まれていなくても、ほかの指定タームとの関連性が高いとOmegaが判断したドキュメントは、検索結果として提示される)。また、NEARおよびADJキーワードを使えば、指定したタームが互いに近い場所に現れるドキュメントを探すことができる。これらのキーワードには違いがあり、ADJの場合は順序が重視され、ADJより前に指定したタームがADJの後ろで指定したタームよりも前に現れるドキュメントがヒットする。一方、NEARの場合は、それぞれのクエリタームがドキュメント内の近い場所に現れていなければならないが、その順序は問われない。デフォルトでは、クエリタームどうしが10語以下しか離れていない場合に、NEARおよびADJにおける近さの基準が満たされる。この基準は、NEARまたはADJのあとに「/n 」(nはクエリタームどうしを隔てている単語の数)を追加することで変更できる。
あるフレーズへの厳密な一致を求める場合は、二重引用符(”)で囲んで指定すればよい。なお、スラッシュ(/)またはアットマーク(@)を含むクエリタームは、自動的にフレーズクエリとして処理される。また、大文字を含むクエリタームは、固有名詞と見なされ、検索前のステミング(語幹処理)の対象外となる。通常、インデックス内のテキストは、より基本的な形への単語の変換を行うステミングという処理を受ける。たとえば、stemmer、stemming、stemmedという3つの関連語はいずれもstemに変換される。詳細については、プロジェクトのクエリ構文のページを参照してほしい。
Omegaは、それぞれのファイルに関するメタデータのインデキシングも行ってくれる。こうしたメタデータをクエリに含めて得られる結果を限定するには、クエリタームに大文字のアルファベット1文字とメタデータによる制限を追加すればよい。たとえば、omindexで「--url /howto」と指定してインデキシングされたファイルは、「/howto」というパス名のメタデータフィールドを持つことになる。そうしたインデキシングを行ったあとに、膨大な数のWebサイトが含まれたOmegaインデックスからEthernetに関するHOWTOだけを探したい場合は、「ethernet P/howto」(「P」はパス名フィールドを表すプレフィックス)というクエリを使えばよい。その他のプレフィックスの詳細についてはドキュメントを参照のこと。
omegaを呼び出す際のFMT CGIパラメータを変えれば、使用するテンプレートを変更できる。FMTパラメータは、Omegaで使用するページの“フォーマット”を表している。
FMTパラメータで指定するページ形式の例として、“topterms”がある。これは、検索結果だけでなく、クエリの改良に役立ちそうな追加のクエリタームもOmegaに提示させるものだ。また、“godmode”というページ形式を使えば、IDによってドキュメントを検索したうえで、それらのドキュメントを検索で探し出すためのクエリタームの一覧を確認することができる。もちろん、あるドキュメントを探し出すためのクエリターム(識別語)のリストは非常に長くなる可能性があるので、ユーザによるシステムリソースの占有を避けるには、godmodeの利用を制限するか無効にする必要があるだろう。godmodeが役に立つのは、検索機能を強化する方法を学ぶときである。また、FMTパラメータを“xml”に指定すれば、HTML形式のWebページではなく、XML形式で検索結果を生成できる。
XapianとOmegaを利用すれば、フルテキストとメタデータの双方を使ったWebサイトの検索が行える。また、Omegaによって検索結果をXML形式のページで取得し、その結果に後処理を加えて直接Webサイトに取り込めば、CGIプログラムを利用しなくても済む。このように、OmegaのWebページをそのまま取り込むことで、ルックアンドフィールを損なうことなくサイトに検索機能を手軽に追加できる。また、XapianとOmegaは、近傍検索など、特に上級ユーザを喜ばせる高度な機能もサポートしている。
Ben Martinは10年以上もファイルシステムに携わっている。博士号を持ち、現在はlibferris、各種ファイルシステム、検索ソリューションを中心としたコンサルティングサービスを提供している。