Webアプリケーション向けのセキュリティスキャナ「skipfish」を使う
近年では多くの分野でWebアプリケーションが使われるようになり、大量の個人情報や重要な秘密情報を扱うようなアプリケーションも少なくない。そのため、Webアプリケーションも攻撃対象として狙われやすくなっている。今回はWebアプリケーションのセキュリティ対策として、Googleが公開しているセキュリティ調査ツール「skipfish」を使ったセキュリティスキャンを紹介する。
Webアプリケーションに特化したセキュリティ調査ツール「skipfish」
今日では、Webブラウザ経由でさまざまな操作を行えるWebアプリケーションが広く浸透している。Webブラウザは最近のほぼすべてのPCにインストールされており、専用のクライアントを用意せずにアプリケーションを操作できるというのがその浸透の理由の1つだ。しかし、Webアプリケーションでは簡単にその一部(HTMLやJavaScript)のソースコードを閲覧することができ、また改ざんや細工を加えたリクエストを容易に送信できてしまう。そのため、設計・実装ミスによって簡単に脆弱性が生まれてしまう。Webアプリケーションに対する攻撃手法として有名なものにはSQLインジェクションやコマンドインジェクション、クロスサイトスクリプティング(XSS)、クロスサイトリクエストフォージェリ(CSRF)といったものがあり、これらが広く知られるようになった現在では攻撃を防ぐためのなんらかの仕組みが実装されていることが多いが、それが万全ではない場合や、ミスやバグなどによって特定の条件下で脆弱性が発生する場合などがある。
今回紹介する「skipfish」は、このようなWebアプリケーションの脆弱性の検出に特化したセキュリティ調査ツールだ。Googleが開発・公開しており、実際にGoogle社内でも利用されているという。skipfishではWebサイトに対しクローリングを行ってアクセスできるURLを抽出し、それらに対しさまざまなパターンでのアクセスを行ったり、特定のキーワードや拡張子を組み合わせて問題の発生しそうなURLやリクエストを生成してアクセスすることで調査を行い、その結果をレポートとして出力する。対象とするWebサイトにHTTPでアクセスして調査を行うため、対象を特定のWebアプリケーションに限定せず、どのようなWebサイトに対してでも利用できる。
調査結果はHTML形式のレポートとして出力され、発見された問題点は「潜在的リスク」ごとに色分けされて表示される。ここで検出された問題点のすべてがセキュリティリスクにつながる訳ではないが、問題を発見するための手がかりとしては非常に有用だ。
skipfishの特徴としては、独自にカスタマイズされた高速なHTTPスタックによる高いパフォーマンスと使いやすさ、そして有意なセキュリティ調査を行える点が挙げられる。同社が公開しているプロクシ型の脆弱性検査ツール「ratproxy」など、同社が持つセキュリティ技術がskipfishに投入されており、CSRFやXSS、エンコード関連処理による脆弱性、SQL/XMLインジェクションなどさまざまな問題の検出が可能だ。動作環境はLinuxやFreeBSD、Mac OS X、Windows(Cygwin環境)となっている。
skipfishで検出できる問題点
skipfishで検出できる脆弱性についてはskpifishのドキュメントにまとめられているが、たとえばリスクの高いものとしては次のものが挙げられている。
- サーバーサイドSQL/PHPインジェクション
- GET/POSTメソッドのパラメータにおけるSQL風命令の埋め込み
- サーバーサイドシェルコマンドインジェクション
- サーバーサイドXML/XPathインジェクション
- フォーマット文字列に関する脆弱性
- 整数オーバーフローに関する脆弱性
- PUTメソッドでのLocations受け入れ
これらは悪用されるとデータベースへの不適切なアクセスやサーバー上での想定外の処理実行などを許してしまう可能性があり、非常に危険な脆弱性であると言える。また、skipfishでは脆弱性だけでなく予期しないリクエスト結果の検出やSSL関連の不適切な設定、有効でないリンク、サーバーのエラーといった、脆弱性には直接つながらないがWebサイトの管理・運用には有用な情報も検出してくれる。
なお、skipfishでは直接の脆弱性にはつながらないという理由で、以下の項目については調査を行わない。
- 暗号化されずにやり取りされるCookie
- JavaScriptからのCookie読み取り
- 暗号化されずに送信されるフォーム
- HTML内のコメント
- エラーメッセージ内でのファイルシステムのパスや内部IPアドレスの表示
- サーバーやフレームワークバージョンの表示
- HTTPのTRACEやOPTIONSメソッドサポート
- WebDAVなど一部でしか使われていない技術
これらは通常直接問題になることは少ないが、別のセキュリティ調査ツールでの検出が可能なものもあるため、状況に応じて別のツールを併用することが望ましいだろう。
skipfishのダウンロードとビルド
skipfishはGoogle Codeのプロジェクトページからダウンロードできる。動作環境はLinuxおよびFreeBSD、Mac OS X、Windows(Cygwin)だ。なお、バイナリパッケージは配布されていないため、各自の環境でコンパイルを行う必要がある。
skipfishのコンパイルには、OpenSSLおよびPCRE、libidnが必要だ。たとえばCentOSの場合、openssl-develおよびpcre-devel、libidn-develパッケージをインストールしておけば良い。これらが利用できる環境で配布パッケージを展開し、展開先ディレクトリ内でmakeコマンドを実行すればコンパイルが完了する。
$ tar xvzf skipfish-2.10b.tgz $ cd skipfish-2.10b $ make
skipfishを使う
skipfishはコマンドラインベースで操作するツールであり、GUIは用意されていない。skipfishのビルドが完了すると、makeを実行したディレクトリ内にskipfishというバイナリファイルが作成される。skipfishには多数のオプションが用意されているが、最低限必要なオプションは「-W」および「-o」オプションだ。これらを指定してskipfishを実行するには以下のようにすれば良い。
$ ./skipfish -W <キーワード辞書の保存先ファイル> -o <レポートの出力先ディレクトリ> <クロールを開始するURL> [<クロールを開始するURL2> ...]
まず「-W」オプションだが、これは学習したキーワード辞書の保存先ファイルを指定するものだ。skipfishでは調査対象とするURLを収集するためにWebページをクローリングしていくとともに、キーワードが格納された辞書を利用して生成された未知のURLに対してもアクセスを試みる。
skipfishにはあらかじめいくつかの辞書がdictionariesディレクトリ以下に同梱されているほか、クローリングに使用したURLやページ内に含まれるURL、文字列などからキーワードを抽出して独自の辞書を生成する機能も用意されている。
ここで生成された辞書データは、-Wオプションで指定されたファイルに保存される。-Wオプションは必須のオプションであるが、もし辞書を保存したくない場合、「-W /dev/null」、もしくはそれと同じ挙動を行う「-W-」オプションを指定すれば良い。また、存在しないファイルを指定することはできないので、新たに辞書を作成したい場合は空のファイルをあらかじめ作成しておく必要がある。
レポートの出力先ディレクトリを指定する「-o」オプションも必須である。そのほかのオプションについては、「–help」オプション付きでskipfishを実行することで確認できる(主要なものについては後述する)。
なお、skipfishでは対象とするWebサーバーに連続してアクセスを行う関係上、サーバーに負荷をかける点には注意したい。フォームへの投稿なども行うため、実際に運用中のサーバーに対して実行することは避けることが望ましい。
使用する辞書を指定する
skipfishのdictionariesディレクトリ以下には多くのサイトで利用できる汎用性の高いキーワード辞書が付属しており、これを使用することで意図せずに公開されているファイルや不適切な挙動を行うURLを検出できる。
dictionariesディレクトリに用意されている辞書は、最小限のものに絞った「minimal.wl」および中程度のキーワードを含む「medium.wl」、多くのキーワードを網羅した「complete.wl」、そして拡張子に対するチェックのみを行う「extensions-only.wl」の4つだ。併用する辞書は、-Sオプションで指定できる。たとえばcomplete.wlを使用してスキャンを行うには以下のようにする。
$ ./skipfish -S dictionaries/complete.wl -W <作成する辞書ファイル> -o <出力ディレクトリ> <クロールを開始するURL>
skipfishによるスキャンを高速化する
skipfishでは辞書やサイトから抽出したキーワードからURLを生成してスキャンを行うため、存在しない膨大なURLに対してのアクセスを行うことになる。そのため、辞書やキーワードの利用を制限してスキャンを高速化するためのオプションも用意されている(表1)。ただしスキャンが高速になるということは、そのぶん脆弱性の「発見漏れ」が生じる可能性も高くなる点に注意が必要だ。
| オプション | 説明 |
|---|---|
| -L | サイトコンテンツからのキーワードの抽出を行わない |
| -Y | 辞書から「<ファイル名>.<拡張子>」というURLを生成する際、一部の組み合わせしか使用しない |
| -W- | 抽出したキーワードを辞書へと書き込まない |
たとえば、skipfishのドキュメントでは「もっとも高速だが一般的な用途には推奨できないオプション」として、以下のような「-W-」および「-L」オプションの併用が挙げられている。
$ ./skipfish -W- -L -o <出力ディレクトリ> <クロールを開始するURL>
このオプションを指定した場合、スキャン時間は短くなるものの、ディレクトリに対する総当たり攻撃が不十分になるという。短時間でスキャンを済ませたいのであればプリセット辞書「extensions-only.wl」もしくは「complete.wl」を使用し、-Yオプション付きでskipfishを実行するのがおすすめだ。
$ ./skipfish -S dictionaries/extensions-only.wl -W <作成する辞書ファイル> -Y -o <出力ディレクトリ> <クロールを開始するURL>
$ ./skipfish -S dictionaries/complete.wl -W <作成する辞書ファイル> -Y -o <出力ディレクトリ> <クロールを開始するURL>
もちろん、-Yオプションを指定すると辞書中のキーワードの一部の組み合わせしか使用されないので、時間的な余裕があるのであれば-Yオプションを使わないほうが好ましい。たとえば以下の例は、指定したWebサイトに対して完全なスキャンを実行するものだ。
$ ./skipfish -S dictionaries/complete.wl -W <作成する辞書ファイル> -o <出力ディレクトリ> <クロールを開始するURL>
ログインが必要なサイトに対する調査を行う
アクセスの際に何らかの認証が必要となるWebサイトに対して調査を行いたい場合、skipfishに認証情報を与えて実行させる必要がある。たとえばBASIC認証を利用している場合、-Aオプションで以下のようにそのユーザー名およびパスワードを指定できる。
-A <ユーザー名>:<パスワード>
いっぽう、Cookieを使った認証を行っている場合は-Cオプションで以下のようにアクセスの際に送信するCookieを指定できる。
-C <Cookie名>=<値>たとえば名前が「sid」、値が「foobar」というCookieを利用する場合、以下のように指定すれば良い。
-C sid=foobar
特定のディレクトリを無視する
Cookieを使った認証を行っている場合、特定のURLにアクセスすると認証が解除されてしまう(ログアウトされる)場合がある。これを防ぐには、-XオプションでそのURLを指定しておけば良い。-Xオプションは指定されたURLを調査対象から外す働きをするオプションだ。たとえば「/logout/」というURLを対象外とするには、以下のオプションを追加すれば良い。
-X /logout/
skipfishのレポートを確認する
skipfishを実行すると、図1のようにその進捗が表示される。なお、テストで使用したのはさくらの専用サーバ エクスプレスG2シリーズのXeon 4コア仕様(ストレージはSATA)で、ローカルで実行しているWordPressベースのWebサイト(記事数は約400)に対しスキャンを行ったが、スキャンの完了までに約12時間ほどの時間が必要だった。
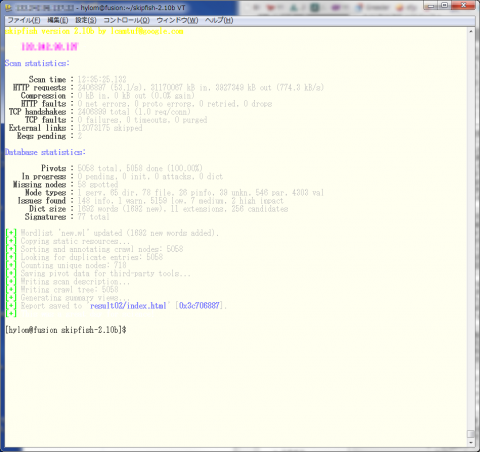
スキャンレポートは、-oオプションで指定したディレクトリ内にHTML形式で保存される(図2)。
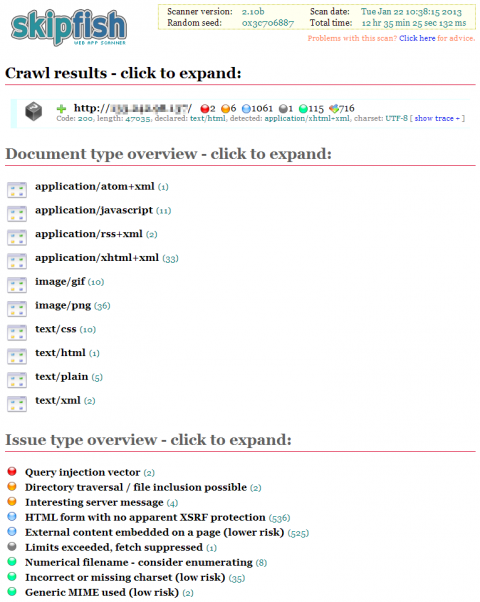
レポートには「Crawl results」および「Document type overview」、「Issue type overview」という3項目が用意されている。まずCrawl resultsだが、ここにはサイトに対してクローリングを行っている際に検出された問題点が表示される(図3)。
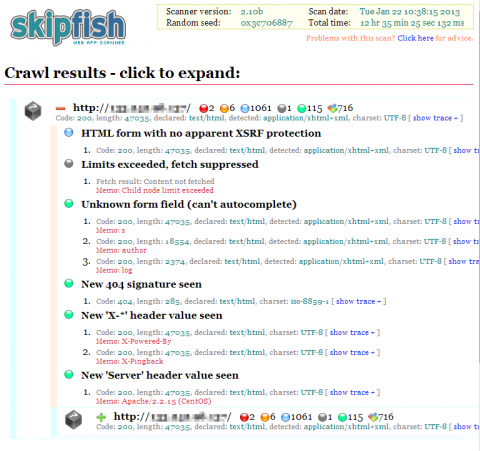
アイコンの色は危険度の高さを表しており、赤が「高リスク」、オレンジが「中リスク」、青が「低リスク」、灰色が「内部的な警告」、緑が「(リスクとは直接関係ないと思われる)情報」となっている。また、「Memo」ではとして発見された問題に関する情報が表示される。
たとえばこの例の場合、リスクの高い問題は発見されていないものの、XSRF対策がされていない可能性のあるフォームがあることが検出されている。
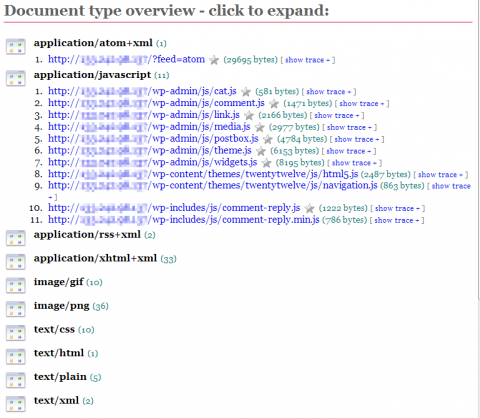
次の「Document type overview」では、クロールや辞書によって生成されたURLに対するアクセスに対し、どのようなドキュメントタイプのコンテンツが返されたかが表示される(図4)。
そして最後の「Issue type overview」では、発見された問題点がその種別ごとに表示される(図5)。
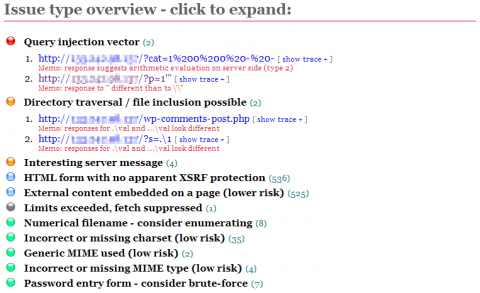
たとえばこの例では、危険度高の「Query injection vector」が2件、危険度中の「Directory traversal / file inclusion possible」および「Interesting server message」がそれぞれ2件および4件、そのほか低リスクのものとしてXSRF対策がされていないフォームや外部コンテンツの埋め込みといったものが検出されている。
手軽にWebサイトの問題点を検出できるものの過信は禁物
skipfishは手軽にWebサイトの問題点を検出できるのが利点である。いわゆる脆弱性の検出だけでなく、キーワード辞書を使ったテストではバックアップファイル(拡張子が「.bak」のファイルや末尾に「~」が付いたファイルなど)の検出、公開状態にあるディレクトリの検出など、よくありそうなうっかりミスによる情報漏洩対策などにも有用だ。Webサイトの問題点というとSQLインジェクションなどの高度なテクニックを利用するものだと思いがちではあるが、このような問題は単純なだけに気がつかないうちに発生している可能性も高いのである。定期的にスキャンを実行して問題がないかチェックすることで、セキュリティに対する意識を高めることができるのではないだろうか。
ただし、skipfishで検出されたものはそのすべてが必ずしも脆弱性につながるものではなく、誤検出であるものもある。そのため、検出された問題点をそのまま鵜呑みにせず、必ず手作業でのチェックやソースコードなどの確認などを行って本当に脆弱性につながるものかどうかを判断してほしい。